Your firewall can block AI crawlers while your robots.txt waves them in
I was auditing a client’s site recently and the same page kept coming back differently.
The first 3 requests pulled the full thing, all 136KB of it. Requests 4 and 5 came back as a stub with a JavaScript challenge and an HTTP 202.
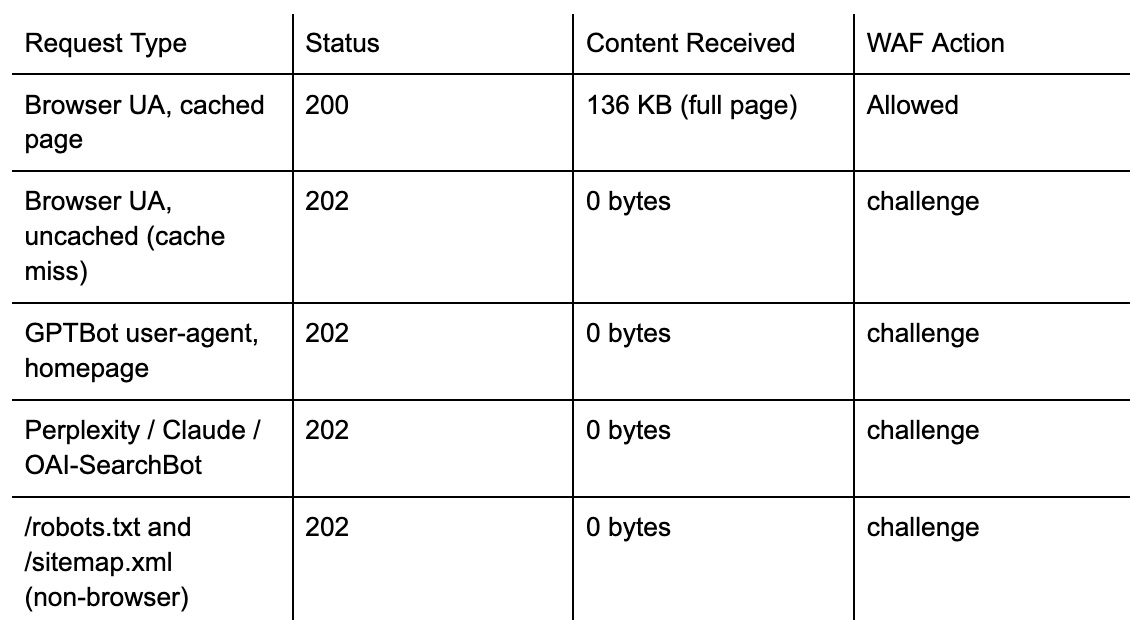
That 202 is the tell. It’s AWS WAF firing its challenge action.
The client’s rate rules were tuned so tight that after 3 hits from 1 IP, the firewall stopped serving the page and started serving a silent puzzle instead.
In a browser you’d never catch it.
The challenge solves itself in the background and the page loads like normal. To an AI crawler it’s a brick wall, because the bots that read your pages for ChatGPT, Claude and Perplexity don’t run JavaScript. They get handed the challenge and nothing else.
And AI search doesn’t stop at 1 page. To build a decent answer an agent pulls several of yours in a single session. It clears the first 2 or 3, trips the rate limit, and gets locked out of the rest.
So it does the rational thing and gives up on you, reaching for some third party talking about you instead. You lose the page, and you lose the story that gets told about you.
That’s the part that stings. The bots that can actually hand you AI visibility are the worst equipped to fight past your security. Your robots.txt is a polite request.
Your firewall is the bouncer, and right now it might be turning away the exact guests you want in.
The fix isn’t a blanket rate limit, since that’s what caused it. Allowlist the AI crawlers by their published IP ranges and confirm them with a reverse DNS lookup rather than trusting the user-agent string, which anyone can fake.
If you genuinely want out of model training, say so in robots.txt for GPTBot, ClaudeBot and CCBot, and leave the search fetchers that feed live answers alone.
Checking all this by hand means reading firewall configs and firing test requests under a pile of different bot identities. So I built a tool that does it for you. Paste a domain into the AI Crawler Access Checker and it hits your site as GPTBot, ClaudeBot, PerplexityBot and the live fetchers, reads your robots.txt line by line, fingerprints your firewall, and times your server for the 499 timeout that quietly drops pages too slow to answer in real time.
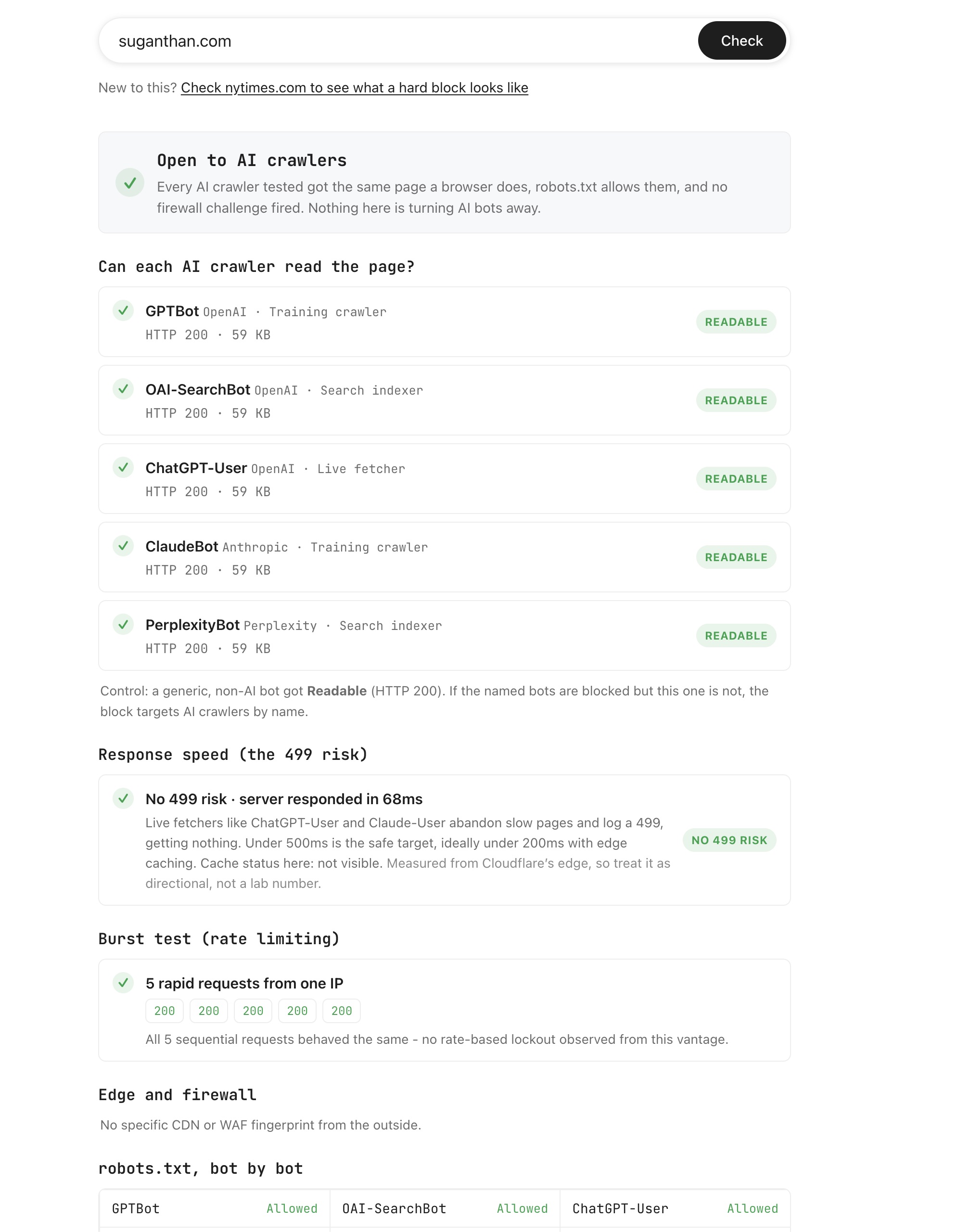
Most people run it braced for bad news about robots.txt and find that file is fine, while their edge is the thing quietly closing the door.
Worth 30 seconds to know which side of that you’re on.