Cloudflare Markdown for Agents. I Tracked Every AI Request for 44 Days.
Cloudflare has a beta feature that serves clean markdown to AI agents. I enabled it, built a tracking layer, and logged every request for 44 days. 1,421 requests. Claude was the second biggest consumer. Here is everything I found.

Most AI visibility tools tell you which bots visited your site. GPTBot showed up 47 times last Tuesday. PerplexityBot crawled your blog. Riveting stuff. That is log analysis with a fresh coat of paint.
I wanted to answer a different question. Not “who visited” but “who specifically asked for my content in a format optimised for AI consumption, and what did they do with it?”
Cloudflare has a beta feature called Markdown for Agents. When a client sends an Accept: text/markdown header, Cloudflare converts the page to clean markdown on the fly. No navigation, no JavaScript, no cookie banners, no noise. Just the content.
The bot has to specifically request it. Browsers don’t send this header. Most crawlers don’t either. But some do. And I wanted to know exactly who, how often, and which pages they cared about.
So I built a tracking layer on top and left it running.
44 days later, I have answers. Some expected, some genuinely surprising.
What Markdown for Agents actually is
This is not llms.txt. That is a different thing entirely.
llms.txt is a static file that sits at the root of your domain, like sitemap.xml. It lists your pages and describes what each one covers. It tells AI crawlers “here is what exists on my site.” It is a directory.
Markdown for Agents is content negotiation. When an AI agent requests a specific page and includes the Accept: text/markdown header, Cloudflare intercepts the response and converts the HTML into clean markdown before sending it back. The agent gets the same content, just stripped of everything that makes HTML noisy for a language model to parse.
One tells crawlers what exists. The other changes how the content gets delivered when they come to read it.
They solve different problems. You probably want both.
How I set it up
Enabling Markdown for Agents on Cloudflare takes about 30 seconds. It is a toggle in the dashboard under your zone settings. The feature is still in beta, so you may need to request access.
The tracking layer took longer. I built a Cloudflare Worker that intercepts every request to my site and checks for the Accept: text/markdown header. When it finds one, it logs the path, a simplified user agent string, and a timestamp to Cloudflare KV storage. The worker does not block, modify, or interfere with the response. It just observes.
The stats endpoint lives at a separate .workers.dev subdomain because Cloudflare Pages takes priority over Workers on the same domain. A small gotcha that cost me 20 minutes of debugging.
Every request gets logged individually with a 45 day TTL for detailed analysis. Daily aggregates get stored permanently. The whole thing runs on the free tier.
It does not work everywhere
Before I enabled it on suganthan.com, I tried it on Keyword Insights, the SaaS I co-founded. Sent a curl request with the Accept: text/markdown header. Got back raw HTML. Not markdown. Just the full page source dumped into the terminal.
Matt Silverlock from Cloudflare replied and identified two limitations the documentation does not mention clearly.
The feature fails silently when the origin server uses chunked transfer encoding (no Content-Length header in the response) or when the page payload exceeds 1MB. Keyword Insights runs on WP Engine, which uses chunked encoding by default. No content-length header means Cloudflare cannot buffer and convert the response to markdown. It just passes through the HTML untouched.
Since I could not easily disable chunked encoding on WP Engine’s infrastructure, Keyword Insights still serves HTML to AI agents even with the toggle enabled. suganthan.com runs on Cloudflare Workers with static assets, so neither limitation applies. Every page is well under 1MB and responses include a content-length header.
If you enable this and it does not seem to work, check those two things first. Run curl -H "Accept: text/markdown" "https://yoursite.com/" -v -o /dev/null 2>&1 | rg 'content-' and look for content-length in the response headers. If it is missing, markdown conversion will not trigger.
44 days of data
The experiment ran from 7 March to 19 April 2026. Here is everything.
Volume
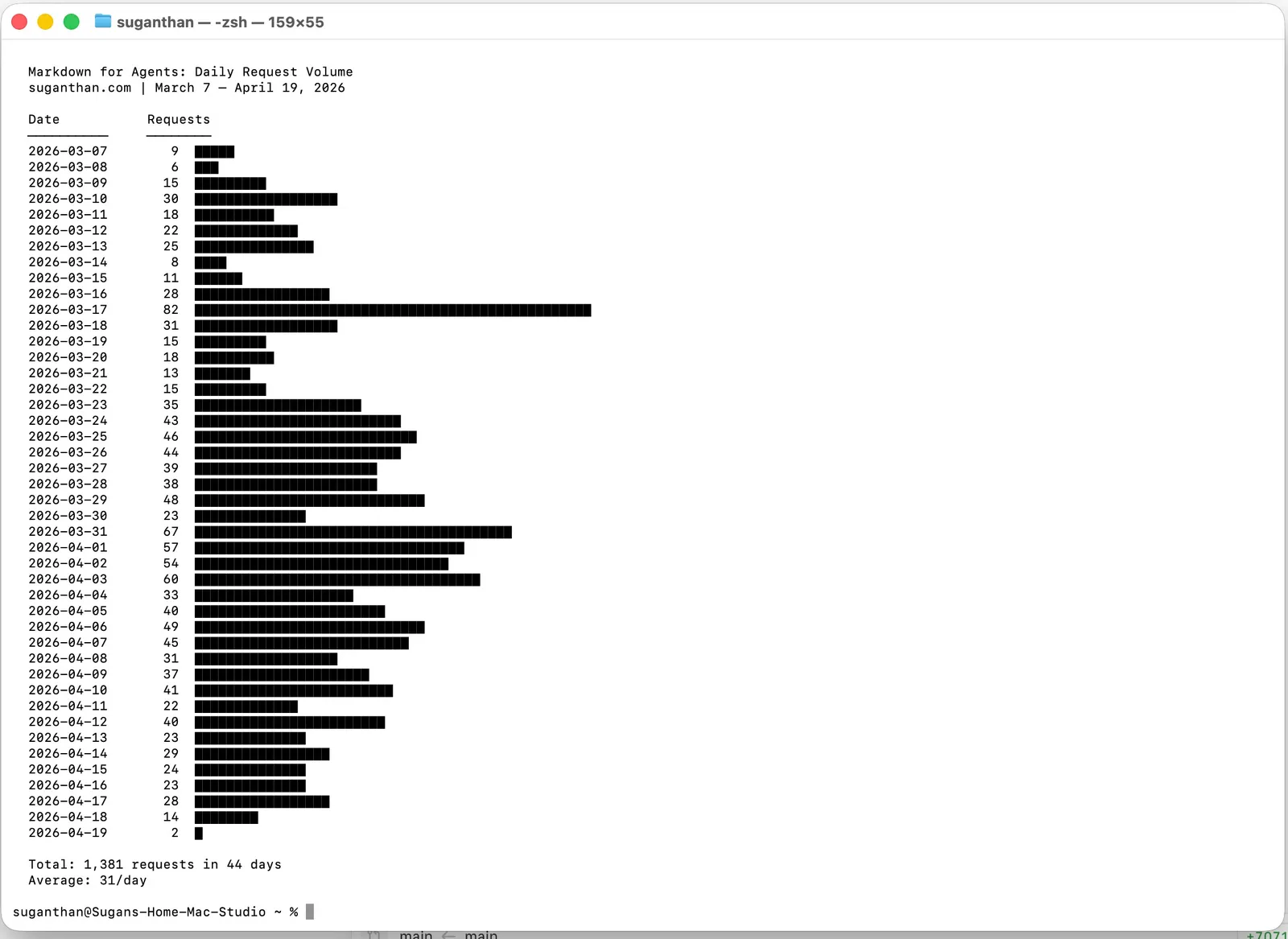
1,421 total markdown requests across 44 days. That is roughly 32 per day on average.
But the average hides the trend. Early March started at about 15 requests per day. By late March it climbed to 40. April settled around 30. The volume grew and held. This was not a spike that faded.
Who is requesting markdown
| User Agent | Requests | What it is |
|---|---|---|
| Chrome (headless) | 639 | Headless browser pools in RAG and retrieval pipelines |
| Claude | 500 | Anthropic’s own infrastructure |
| axios | 211 | Node.js HTTP library, commonly used in AI data pipelines |
| curl | 13 | Manual or scripted fetches |
| markdown.new/1.0 | 6 | Dedicated markdown fetching service |
| qodercli/1.0 | 3 | Qoder, an AI coding tool |
| MarkdownWorker/1.0 | 1 | Another markdown specific fetcher |
The Chrome headless pool at 639 requests is the largest group. These are not real browsers. No human opens Chrome, manually sets an Accept: text/markdown header, and browses a blog. These are automated retrieval pipelines running headless Chromium instances.
Claude at 500 requests is the one I did not expect. Anthropic’s own infrastructure is actively requesting markdown from my site via content negotiation. That is not ClaudeBot (their announced web crawler). This is something else in their stack that specifically asks for markdown when it is available.
The new user agents are worth noting. markdown.new, qodercli, and MarkdownWorker did not exist when the experiment started. They appeared in the data during April. The ecosystem around this standard is growing in real time.
What they are reading
| Page | Requests |
|---|---|
| Google Search Console MCP Server guide | 457 |
| VisionClaw (OpenClaw on Meta Glasses) | 306 |
| OpenClaw for SEO | 148 |
| How to Connect Ahrefs MCP Server to Manus | 57 |
| robots.txt | 56 |
| BigQuery MCP Server guide | 41 |
| How to Use the Wayback Machine to Recover Lost Content | 33 |
| Homepage | 26 |
The GSC MCP guide alone accounts for 32% of all markdown requests. That post is also my highest traffic page from traditional search. AI retrieval systems are gravitating toward the same content that performs well in Google. Whether that is cause or correlation, I cannot tell from this data.
56 requests for robots.txt is interesting. Somebody is checking whether the site has crawling restrictions before pulling content. That is polite crawler behaviour.
The Day 10 crawl
On 17 March, 10 days into the experiment, something unusual happened. A single crawler hit every page on the site. Systematically. One page every 50 seconds, 82 requests in total. (I wrote about it here)
It rotated between 3 different user agent strings. Windows Chrome, Mac Chrome, Linux Chrome. Classic headless browser pool behaviour. The timing pattern was mechanical, perfectly spaced.
The user agents were not any of the known bots. No GPTBot. No PerplexityBot. No ClaudeBot. Just standard Chrome strings requesting markdown specifically.
Somebody’s retrieval pipeline has adopted this standard and was building an index of sites that serve markdown to AI agents. I still do not know who it was.
What this proves and what it does not
I want to be precise here because it matters.
What the data proves
AI agents are actively using content negotiation to request markdown. 1,421 times across 44 days, from multiple independent systems. The Accept: text/markdown standard is being adopted before the major crawlers have even implemented it.
The adoption is growing. Volume went up, new user agents appeared, and the trend held steady through April. This is not an anomaly or a one-off crawler.
Claude’s infrastructure (not ClaudeBot, something else) is a major consumer. 500 requests is 35% of all traffic. Anthropic built this into their stack.
What the data does not prove
That AI crawlers prefer markdown over HTML. I only log requests that include the Accept: text/markdown header. I have no visibility into whether these same systems also fetch the HTML version. I am measuring one side of the equation.
That serving markdown improves your chances of being cited in AI generated answers. The tracking layer logs inbound requests. It cannot track what happens downstream. Whether these requests led to citations in ChatGPT, Claude, Perplexity, or any other AI system is completely invisible to me.
That this drives traffic. There is no data connecting markdown requests to actual visits from AI search results or referrals from AI products.
I tried to close this gap using Ahrefs Brand Radar, which tracks AI citations across ChatGPT, Perplexity, Gemini, and Google AI Overviews. It would have let me cross reference “which pages get the most markdown requests” with “which pages get cited most in AI answers.” But Brand Radar is a paid add-on I do not currently have enabled. So the correlation analysis remains undone. I will get this enabled and test it again.
What to track next
The experiment answered Phase 1. “Is anyone requesting markdown?” Yes. Definitively.
Phase 2 is the harder question. “Does serving markdown actually improve your visibility in AI generated answers?”
To answer it, you would need citation tracking. Specifically, which of your pages are being cited in AI responses, and does that correlate with markdown request volume? The tools exist. Ahrefs Brand Radar tracks citations across all major AI platforms. The cross-reference is straightforward once the data is available.
The strongest test would be an A/B approach. Serve markdown on some pages, disable it on others, and compare citation rates over 60 or more days with enough volume to draw real conclusions. That requires more traffic than my site generates, but for a larger publisher it would be a clean experiment.
For now, the practical recommendation is simple.
Enable it.

Cloudflare Markdown for Agents costs nothing, takes 30 seconds to activate, and the downside is zero. If AI systems are already requesting markdown and you are not serving it, you are leaving the door closed to a visitor who specifically knocked.
Whether that visitor tells their friends about you is still an open question. But at least let them in.
Want your site readable to AI agents efficiently?
If you want help applying this on your own site, my agency Snippet Digital takes on this kind of work. Send an enquiry and I will be in touch.
Work with meWant my posts to show up more often on Google?
One click and Google will surface this site in your Top Stories.



Norwegian entrepreneur with 20+ years in SEO. Co-founder of Keyword Insights and Snippet Digital. Based in Dubai.