How ChatGPT Actually Picks Sources (I Read the Network Traffic, Not the Outputs)
I read 2 days of ChatGPT's raw network traffic to see how it picks sources, which domains get cited, and how to rank in and get cited by ChatGPT.
I keep getting the same question from clients and SEOs (GEOs?).
“How do we show up in ChatGPT?”
The answer is always the same. Write good content, do listicles, comment on Reddit.
The usual.
But, how do we actually know any of that works? Most of it gets repeated on faith, one expert quoting the last.
So instead of taking it on trust, I spent a few days reading what ChatGPT sends my browser underneath the reply. The raw network traffic, in readable JSON.
This is a walk through what I found, roughly in the order I found it.
Before you quote a number from this, read this. It’s one person, one logged-in Pro account, a few days of traffic, not a population study. I logged about 1,240 source records across a few dozen searches. The structural findings, the fields ChatGPT uses and how they behave, are firm, because you only need to see a field once to know it’s real, and I saw them again and again. The numbers and percentages are a different matter. They come from a small batch of mostly SaaS and tech queries, so treat them as direction, not measurement. I flag which is which throughout.
How this differs from the big visibility studies, and what you can take to the bank
There are two ways to do such a study, and they point in opposite directions.
The big studies, the ones the platforms and the well-funded tools run, fire thousands of prompts, record which brands appear in the answers, and roll that up into share-of-voice reports. Large sample, but black box. They only ever see the finished answer, so they have to infer the machinery underneath from the output.
This is the other way round. I read the network traffic, the JSON the engine sends to my own browser, and lift out the engine’s own internal labels: the result_source it stamps on each result, the turn_use_case it files each query under, the vendor names, the search queries it wrote, the model it actually ran. I’m not measuring how often something happens across a population. I’m documenting that the machine has a thing, and what the machine calls it.
That difference decides what you can trust here, so I am going to be blunt about it.
Two confidence levels, do not mix them up
Structural facts (high confidence)
That result_source exists and carries serp, labrador, bright, oxylabs. That bright is Bright Data and oxylabs is Oxylabs. That there are six turn_use_case values. That text queries skip the web entirely. That Thinking fires dozens of site: and price-verification sub-queries. These are read straight off the wire. One clean capture proves a field exists and what it is named, and a prompt case study, however enormous, cannot see any of it.
Frequency observations (directional only)
Anything with a percentage or a ranking, “70% bright”, “Reddit is the most cited domain”, “YouTube never gets cited”, comes from tens of queries on a single account, and my own query choice skews it. I picked SaaS and tech, which is exactly why Reddit and the tech review hubs lead here; a batch of health or fashion queries would crown different ones. Read these as the shape of the thing, not the measurement. Where a direction has a mechanical reason behind it (Reddit is text so it gets quoted, YouTube is video (metadata) so it does not), trust the direction and ignore the exact number.
First, the boring truth about “packet analysis”
Skip this section if you don’t want to get into nitty gritty technical details.
My first instinct was wrong. You cannot sniff packets and read queries, because the payload is TLS encrypted, so a capture hands you scrambled cipher text for the actual messages. What the capture does leak is the metadata.
The destination hostname, the IPs, and the fact that the ChatGPT app talks over QUIC (HTTP/3), not plain TCP. That is why, in the screenshot below, Wireshark can still show “openai” in the handshake. It reads the unencrypted server name, not the conversation. QUIC obfuscates its first packet with fixed keys from the spec, so a tool can unwrap that opening packet to show the ClientHello.
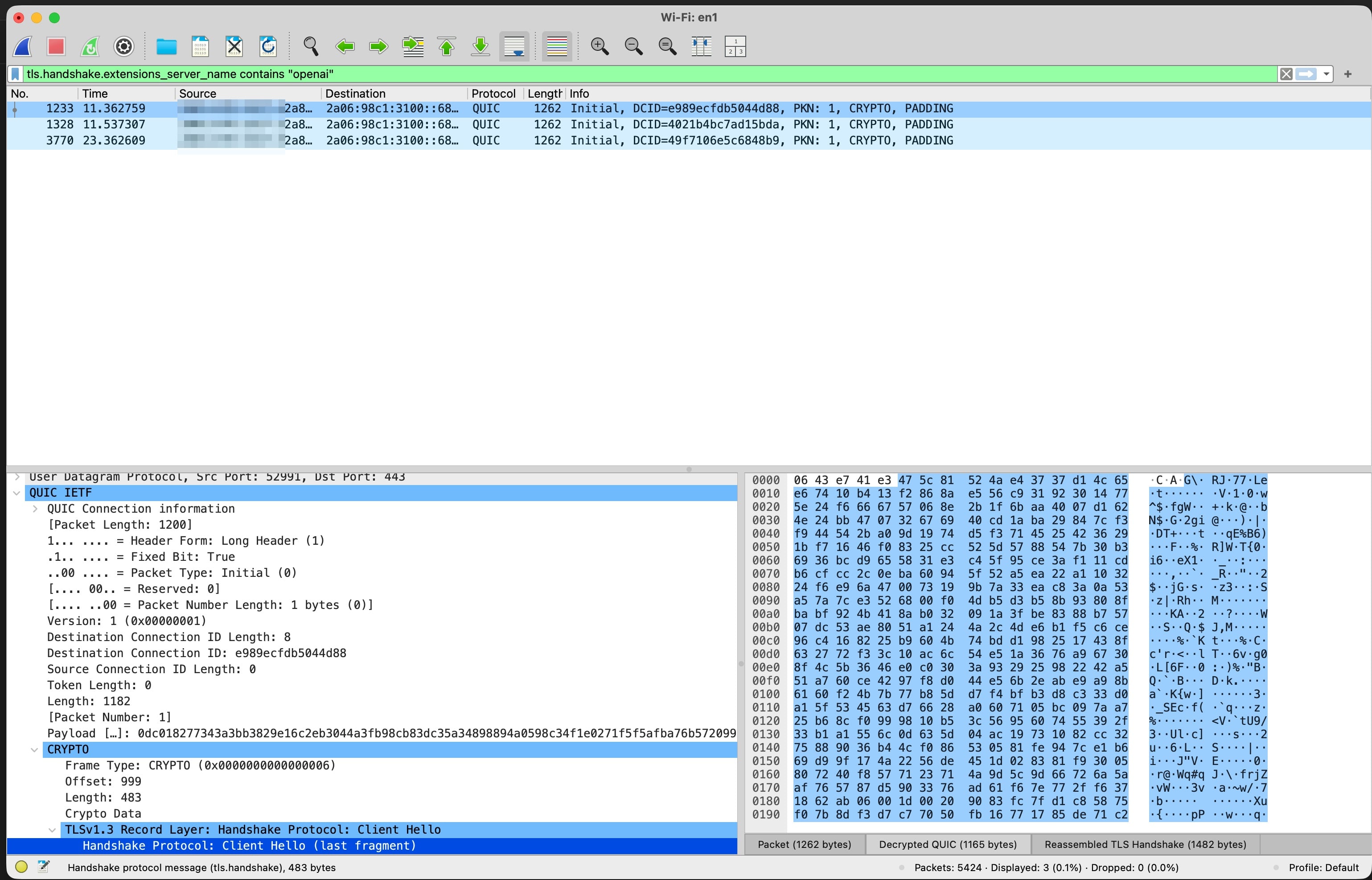
The real request and response bodies sit in later protected payloads that stay unreadable. So the readable layer is the browser itself, after decryption, in the Network panel.
That’s where the queries, the answers, and all the metadata live as JSON.
This is HTTP inspection, not packet sniffing, and it’s worth saying because half the people who try this start with Wireshark and give up. (I know I did lol)
Two things that did not work, so you do not repeat them.
- Driving a clean automated Chrome got me hard blocked by Cloudflare within a few queries on a different engine: the “verifying you are human” wall just loops forever in an automated browser, so I moved to my real Chrome with my real sessions.
- On ChatGPT, the answer never showed up in my capture at first, because it streams over a long-lived connection opened at page load that a hook installed mid-session cannot see. More on both later.
The field that labels every source
I opened DevTools, turned on Preserve log, ran a normal query, and searched the responses for anything that looked like a label.
The field that came back was result_source. It sits on every web result ChatGPT pulls, you never see it in the answer, and it takes 1 of 4 values.
Mark Williams-Cook shared that he had found three of these, I came across the fourth. I then saw Metehan’s post, and it looks like he may have already found it too. But honestly, this is not really about who found what first. It is more about sharing what we are seeing, comparing notes, and learning from each other.
Here’s 1 source from the traffic, trimmed to the fields that matter.
{
"attribution": "TechRadar",
"url": "https://www.techradar.com/best/...",
"snippet": "...",
"pub_date": "2026-05-09",
"result_source": "labrador"
}The 4 values it uses:
result_source | What it is |
|---|---|
serp | The open web baseline, mostly seen on news (Yahoo, StreetInsider) |
labrador | An allowlist of established publishers. Reuters, The Guardian, the WSJ, the FT, Wikipedia, even arXiv. Snippets run to ~1,080 characters, basically full-article extracts |
bright | Bright Data, a commercial web scraper. Dominant for shopping, finance, weather, local. |
oxylabs | Oxylabs, a rival scraper. Regional and local press, some open web |
labrador looks like a licensed tier, several of those publishers have signed content deals with OpenAI, and it isn’t one you get into unless you own a national newspaper.
bright and oxylabs are the interesting pair. The names point at Bright Data and Oxylabs, 2 commercial scraping firms that happen to be direct rivals. I can’t see a contract in the traffic, so I won’t claim ChatGPT pays them, but its open web fetching runs through both, and the field tells you which one fetched each result. (We’ve been Oxylabs customers for a long time for our SaaS Keyword Insights.)
Across everything I logged, bright did the bulk of the fetching, especially on commercial, shopping, finance and weather queries. oxylabs skewed regional and local, labrador stayed on news and reference, and serp mostly turned up on news. To put names to the tiers, labrador carried Reuters, the WSJ, Wikipedia and TechRadar, bright pulled Reddit, Forbes and rtings, and oxylabs brought the Gulf press like Khaleej Times and Gulf News.
I even caught the split inside 1 weather query, bright taking the global data sites like the Met Office while oxylabs handled the local Gulf press. (I live in Dubai btw) In that 1 query the breakdown came out like this.
Source Pipeline
metoffice.gov.uk bright
accuweather.com bright
timeanddate.com bright
khaleejtimes.com oxylabs
gulfnews.com oxylabs
whatson.ae oxylabsThe AI SEO/GEO takeaway
You’re mostly competing in the scraped tier, so be cleanly scrapable. Put your facts and numbers in plain HTML text, never behind a script or inside a PDF or an image. The licensed tier is mostly shut, so the lever you’ve got is third-party coverage, PR, brand mentions, links and Reddit, to land on the pages the scrapers actually reach.
The queries that never reach the web
The next thing I noticed was that some queries produced no network search whatsoever. Before ChatGPT searches, it files your question into a bucket, in a field called turn_use_case. I saw 6 of them across the questions I tried, instant search, shopping, text, local, thinking and image generation.

The one to care about is text. When ChatGPT files your question as text, it doesn’t search. It answers from its training corpus and stops.
The obvious cases end up here, “how do I change a flat tyre”, “write a Python function to merge two sorted lists” and “translate this into 4 languages” all came back text with an empty network tab.
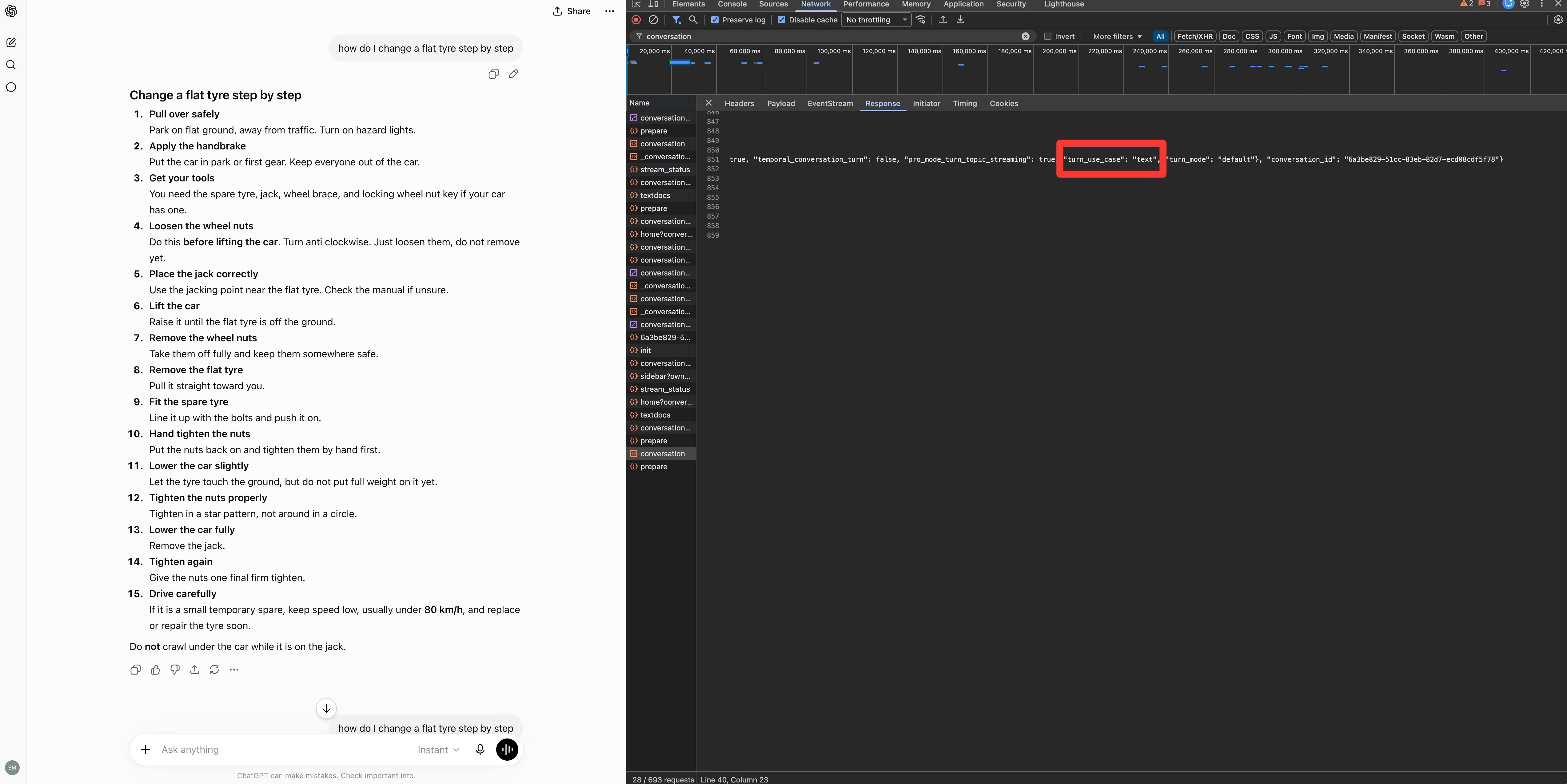
The one that should worry you is that “latest treatment guidelines for type 2 diabetes” also came back text, a current, high-stakes question you’d assume it researches. It didn’t, it answered from training. No EEAT here. Oops!
Of 10 deliberately current questions I tried, 3 were handled this way with no search at all.
The wording decides the bucket, not the topic.
“best coffee near me” flips to the local pipeline, “best 4K TVs to buy” turns on shopping, but “best 4K TVs with reviews” stayed a normal search.
A maths question quietly jumped to a reasoning model under thinking, while “Tesla stock price this week” stayed instant search.
Keep in mind, these are results from my limited testing. I will do more tests when I find some more time.
The AI SEO/GEO takeaway
Before you spend a penny on a page, check the query even searches. If it’s a how-to or a definition it may be answered from training, where no page can get in, however good it is. Spend your effort where it actually fetches.
If you want to be mentioned for such queries, you’d have to spend a lot of time building authority and wait for your brand to be included in future training data. (For example make sure crawlers like Common Crawl can see your site)
How one question fans out into dozens of searches (Fanout queries)
ChatGPT also exposes the searches it runs for you, if you pull the full conversation back from its own API. On the fast model it’s minimal, 1 reworded query and done, maybe optimised for speed over depth. On the thinking model, asked to compare a few products, it ran roughly 15 to 40 sub-queries off the single question. (The number depended on the complexity of the question)
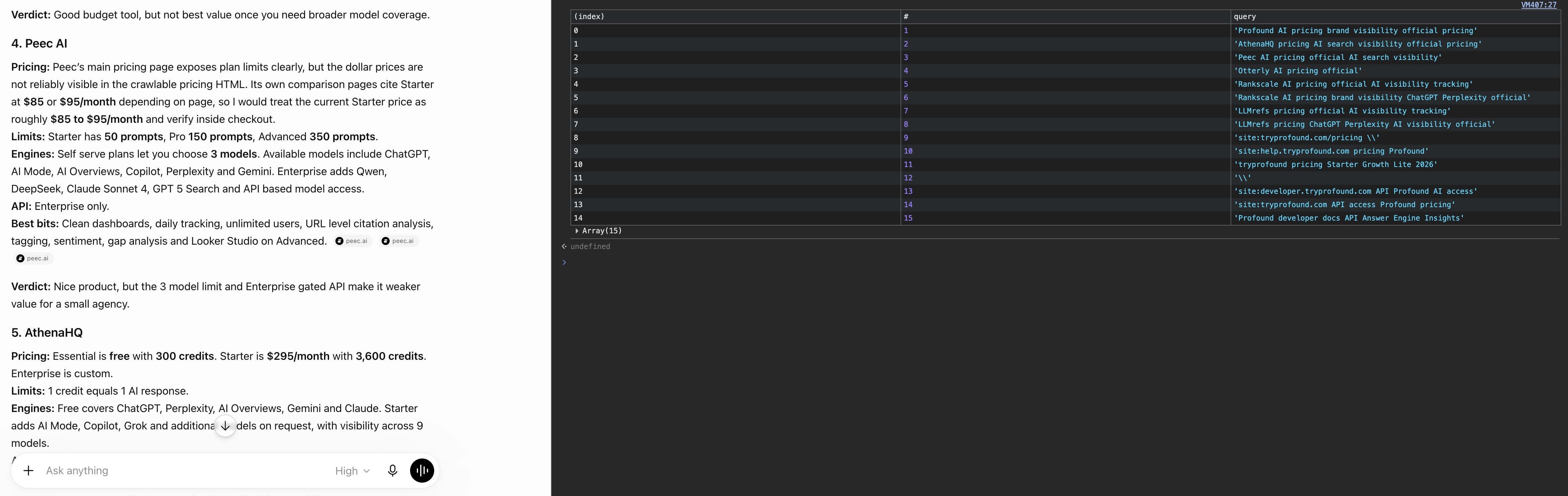
Here’s a slice of what it actually ran for 1 compare task.
"Profound AI search visibility pricing AI engines tracked 2026"
"AthenaHQ pricing AI search visibility tool"
"site:peec.ai/pricing Peec AI Starter Pro Advanced 50 prompts 150 prompts"
"Peec AI pricing $95 $245 $495 official" (a guessed price, then searched to confirm)
"Scrunch AI pricing" (not in my prompt, found mid-research)
...around 40 of these for one comparisonThree things stand out in there. It fires site: probes straight at vendor pricing pages.
It guesses a price and then searches to confirm it. And it keeps widening as it goes, picking up tools you never named and chasing their pricing too.
It doesn’t only search either, the page-reading is just as literal, it ran find for $, €, 99 and even “Agency”, then used the browsing tool’s own open and click commands to pull up the results it wanted, run server-side, not an agent on your screen.
The same happens to your own site. Ask it “keyword insights pricing” and it runs a site:keywordinsights.ai/pricing probe, guesses something like “Starter $58, Pro $145, Advanced $299”, then opens the page and reads the HTML for the currency symbol to confirm.
The AI SEO/GEO takeaway
Put your key numbers and data in plain HTML text, never inside an image, because in this case with pricing it greps the page for $ and € and can’t read a graphic. Also you need to make sure you survive a site:yourdomain.com/pricing probe in this use case and write for the cleaned up query it actually runs, not the messy phrase a person types. Avoid JS based toggles and dynamic data loading.
Fetched, cited and mentioned aren’t the same
This is the distinction people muddle most, so it’s worth being exact. 3 different things can happen to a source.
- Fetched. The model pulls your page into context. This is the
result_sourceobject. The reader never sees it. - Cited. It attaches your page as the source behind a specific sentence, the footnote you can click.
- Mentioned. Your brand name appears in the answer, often as a chip linking to your site, but it isn’t the source of the claim.
They’re 3 separate outcomes, and you can win or lose each one on its own.
To see the gap between them I took a batch of commercial and recommendation queries and split what ChatGPT fetched from what it cited.
This is the small, tech-skewed sample, so read what follows as a pattern, not a number to bank on.
Across that batch, Reddit and YouTube were both fetched heavily, 278 and 201 times. But Reddit was cited 11 times and YouTube not once.
I think the reason is mechanical. A citation has to bind to text the model actually pulled, and when it fetches a YouTube page in search it gets the metadata, not the actual video transcript.
A Reddit thread is all there in the page. This isn’t just my sample either. Ahrefs, across 1.4 million ChatGPT prompts, found Reddit cited at 1.93% against YouTube’s 0.51%, and Profound found the same gap.

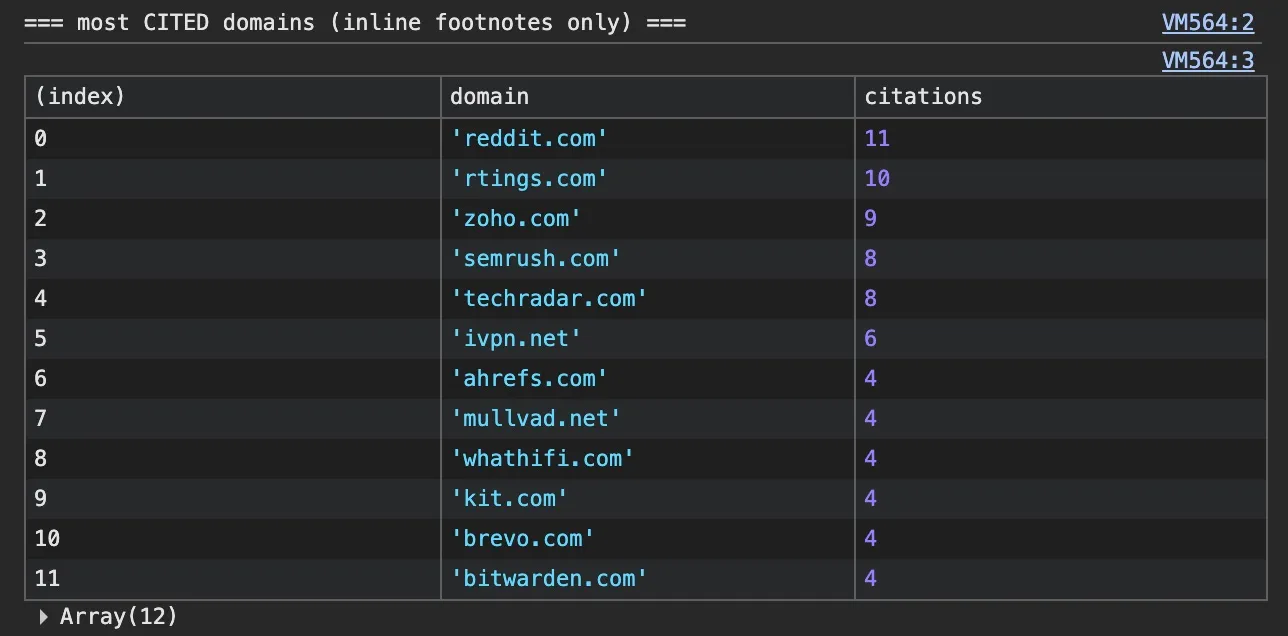
A few other patterns, same caveat on sample size. Reddit was the single most-cited domain, narrowly, and after that no one ran away with it. The citations spread thin across review hubs like rtings and TechRadar and vendor pages cited for their own specs.
Here’s the top of the cited list across that batch.
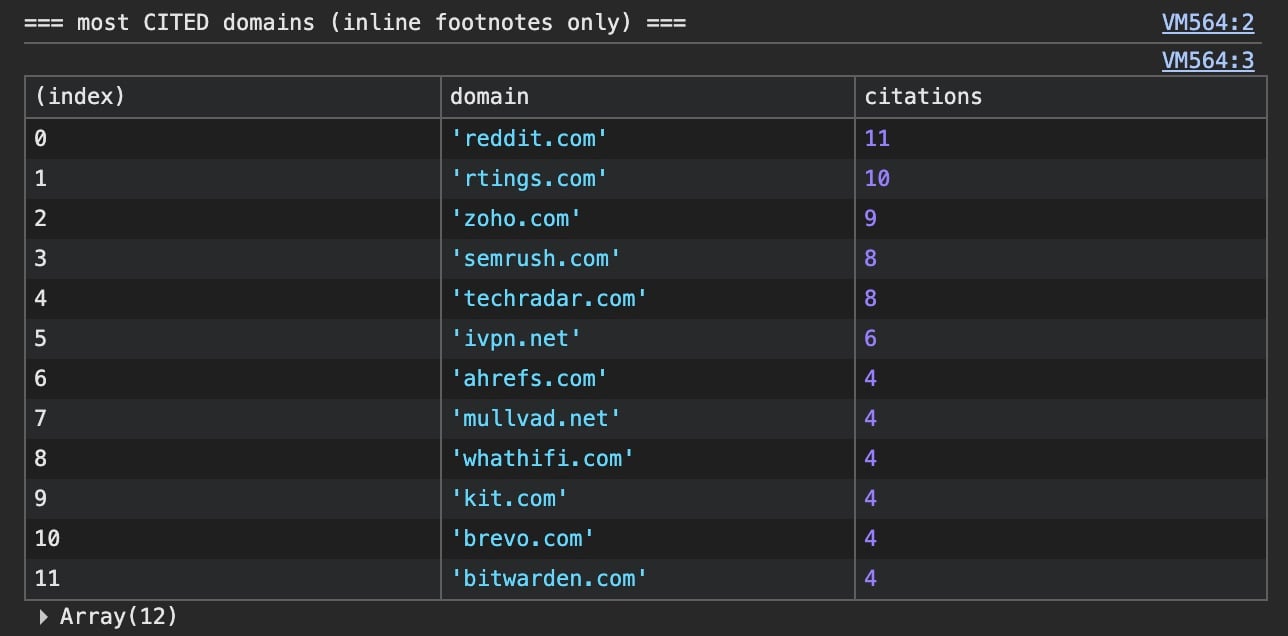
Vendor pages get cited too, but for their own facts, the pricing and specs. Zoho, Semrush and the VPNs earned citations that way. The verdict on which one is best still gets cited to a third party. You can be mentioned without being cited, and cited without being mentioned.
Two mechanics sit underneath this. Citations bind to a specific sentence, not the whole answer, so being topically relevant isn’t enough, you have to be the best support for a precise claim.
And results are deduped by domain, so 20 thin pages from your site collapse into 1.
One strong page per claim beats a pile of weak ones.
So, don’t go around creating thousands of low quality/thin pages to address each fanout query.
The AI SEO/GEO takeaway
You can’t cite yourself. The claim about you gets sourced from someone else, so earn third-party coverage on review sites and Reddit, win on text rather than video, and put 1 strong page behind each claim, because it dedupes by domain.
The model explains its own strategy
I went looking for a hidden ranking score first and found nothing. That kind of logic, a domain authority number, a trust weight, a formula, never reaches your browser, because it stays on OpenAI’s servers.
So anyone selling you “ChatGPT’s ranking factors” is selling you snake-oil.
What the traffic does have is the thinking model’s chain of thought, saved in the conversation, where it describes its own sourcing in plain words.
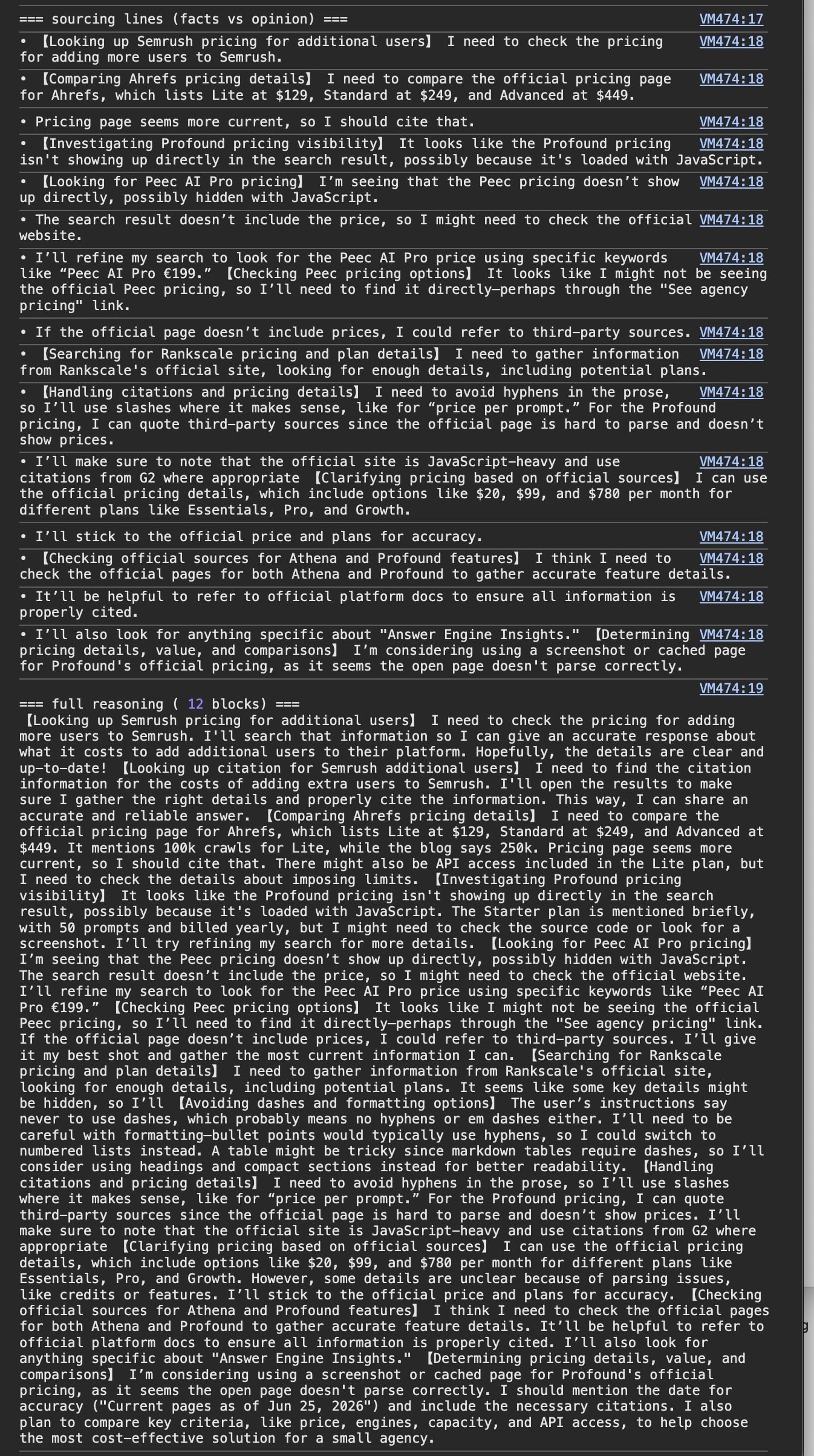
For facts, the pricing and the specs, it goes to the official page first, and it says so.
Comparing Ahrefs, it reads the official page, notes it “lists Lite at $129, Standard at $249, and Advanced at $449”, and decides “pricing page seems more current, so I should cite that”. It wants the source it trusts, and the current one.
Then it hits the wall this whole post is about.
On Profound it reasons that “the pricing isn’t showing up directly in the search result, possibly because it’s loaded with JavaScript”. Same on Peec, where “the pricing doesn’t show up directly, possibly hidden with JavaScript”.
So it stops trying to read them and falls back. “I can quote third-party sources since the official page is hard to parse and doesn’t show prices”, it writes, and it notes it should “use citations from G2 where appropriate”.
That’s the whole game in one trace. The model wanted Profound’s and Peec’s own numbers. Their pricing sat behind JavaScript, so it couldn’t read them, and it cited G2 instead. Your facts, someone else’s page, because yours wouldn’t parse.
Those quotes are the model’s own, from the saved reasoning, not mine.
The AI SEO/GEO takeaway
Own your facts, in plain HTML. Your pricing and spec numbers have to sit in crawlable text, not loaded by JavaScript and not baked into an image, because the model reads the page itself and gives up when it can’t. A JavaScript pricing table doesn’t just rank badly, it hands your numbers to G2.
The opinion you earn separately, through reviews, Reddit and honest comparison content, which is where the recommendation gets cited from. A clean, readable pricing page with no third-party coverage gets your facts read and someone else recommended.
What I could not see
There’s no visible ranking logic, as above, so why 1 source beats another, past the model’s own narration, stays server side.
Personalisation is real and selective.
On a query that overlapped my own work, ChatGPT pulled in my past conversations, with the sources listed as personal_sources: ["convo_search", "gmail", "files"].
It used one of my old chats inside a generic “best tools” answer, but only on 1 of the 3 conversations I checked, the one that matched my history.
So part of some answers is built from a user’s private data you can never optimise for, which is 1 reason 2 people get different answers and visibility scores wobble.
Local is capped. There’s a config value, local_results_limit, set to 2.
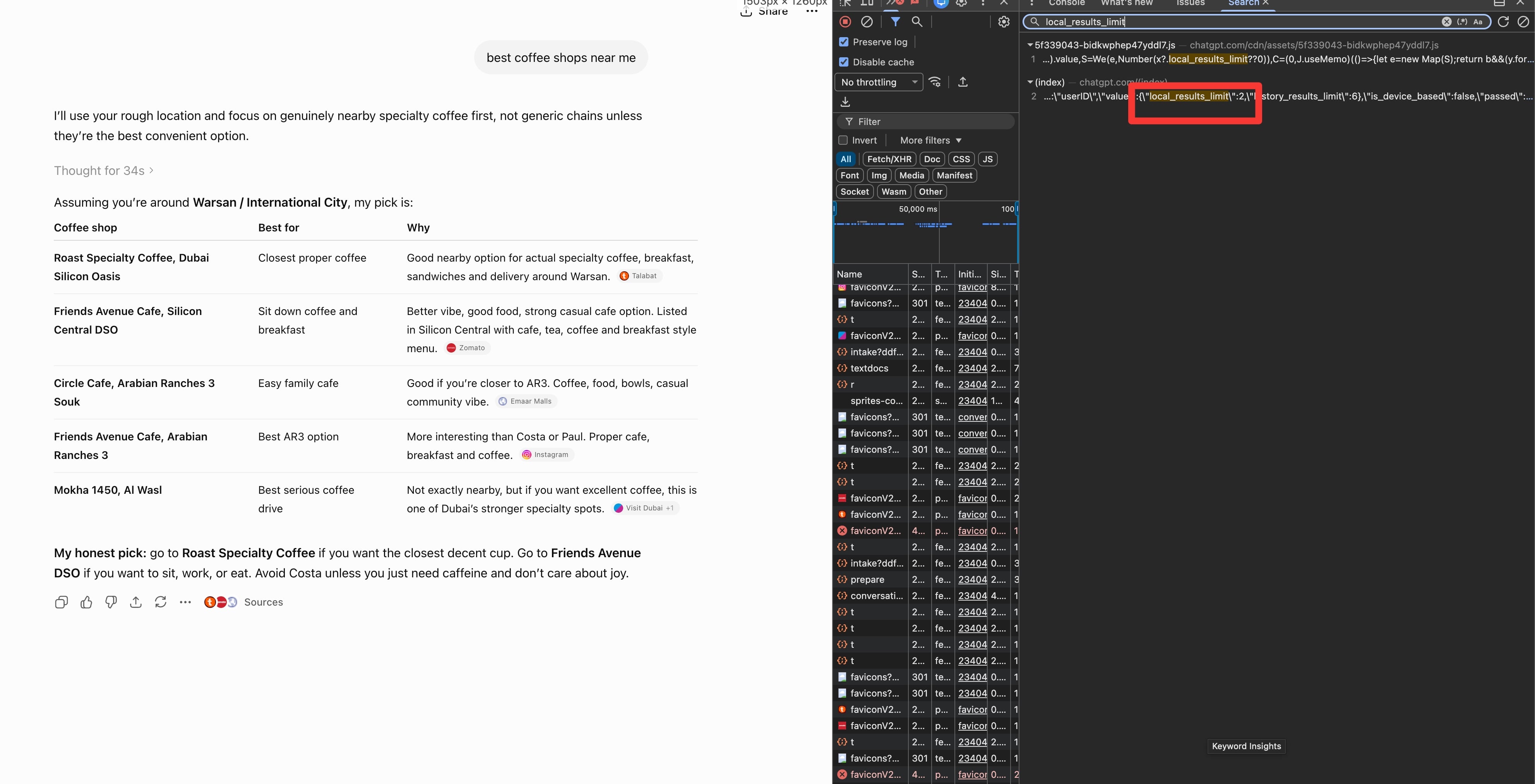
Ask for the best coffee near you and ChatGPT returns 2 places, not a top 10. For local you’re in the top 2 or you aren’t there.
One thing I genuinely can’t call yet. My read on shopping comes from a single shopping query, and it flatly contradicts what Mark saw on his single query, so the shopping mix is unsettled until someone runs a proper batch.
And the wider caveat, said plainly. The structure I’m sure of, because I saw it across roughly 1,240 records. The percentages come from a small batch of commercial queries, mostly SaaS and tech, so they need a bigger run across real verticals before anyone banks on them.
That run is the next piece.
Run it yourself
None of this needs special access or requires you to be connected to the Matrix and become an operator, just your own browser.

Open ChatGPT, press Cmd+Option+I for DevTools, open Network, tick Preserve log, run a query, then press Cmd+Option+F and search the responses for result_source.
That alone shows you the pipeline behind each link.
For the rest, the fan-out and the citations and the reasoning, open the Console, type allow pasting once, and run this against a conversation that searched the web.
const t = (await (await fetch('/api/auth/session')).json()).accessToken;
const c = await (await fetch('/backend-api/conversation/' + location.pathname.split('/c/')[1], {headers: {Authorization: 'Bearer ' + t}})).json();
const rows = [];
JSON.stringify(c, (k, v) => {
if (v && v.result_source) {
const d = (v.attribution || v.url || '?').toString();
rows.push({source: d.replace('https://', '').replace('www.', '').split('/')[0], pipeline: v.result_source});
}
return v;
});
console.table(rows);It reads only your own session, so nothing leaves your machine. The output is a plain table of each source and the pipeline that fetched it.
source pipeline
techradar.com labrador
whathifi.com labrador
soundguys.com bright
rtings.com bright
khaleejtimes.com oxylabs
streetinsider.com serpChange what the loop collects and you can pull the searches, the citations and the reasoning the same way.
A free extension now captures most of this
If pasting scripts into your own console isn’t your thing, there’s now an easier route. I built one.
FanoutFox is a free Chrome extension that reads your own ChatGPT session and lays out what this whole post took apart by hand.
The fan-out queries, the result_source pipeline behind every source, what got cited versus what only got mentioned, and the intent bucket each turn falls into. It’s one click instead of the Console, and it never leaves your browser.
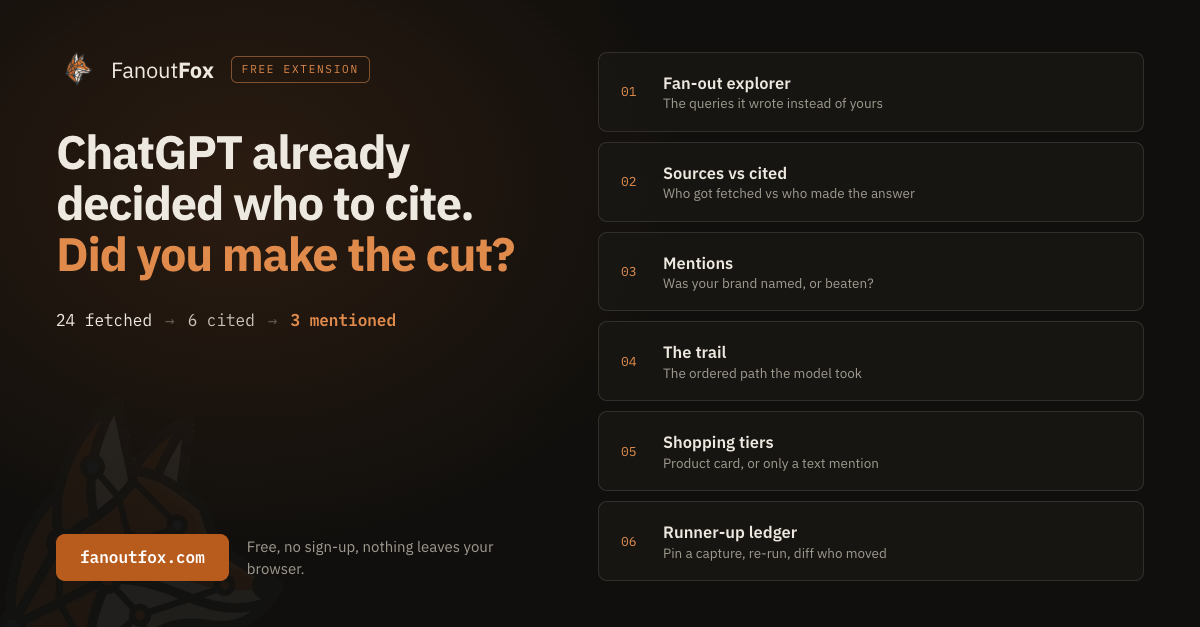
It does the reading for you:
- The
result_sourcepipeline. The scraper behind each cited result, so the Bright Data, Oxylabs, Labrador and SERP split shows up without you touching a line of JSON. - Fetched, cited and mentioned. The three states I kept separating above, shown per source, so you can tell the sources it quoted from the ones it only named.
- The fan-out. Every sub-query one question spawned, the
site:searches and the price checks, listed out in full.
It’s live on the Chrome Web Store, and I took it apart properly in Part 2.
If you’d rather a second option, Olivier de Segonzac also runs a free Chrome extension that pulls ChatGPT’s search and fan-out data.
He read this research and extended it to capture 3 of the signals I took apart above.
- The
turn_use_casebucket. The intent label ChatGPT files each turn under, so you can spot when a query flips to shopping, local ortextbefore it even answers. - The reference-type mix. How many of the answer’s citations were products versus search results, news or images, parsed straight from the reference tokens.
- The
result_sourcepipeline. The scraper behind each cited result, charted per conversation, so the Bright Data, Oxylabs, Labrador and SERP split shows up without you reading a line of JSON.
It runs locally on your own session and exports straight to Excel. Grab it from the Chrome Web Store, and Olivier wrote up the update here.
So, back to the question we opened with. Does the usual advice hold up? Mostly. Reddit earns citations and topped my cited list. Listicles and review sites make up most of the rest. Good content still matters, but only the half the model can actually read. The rest it reads off someone else’s page.
Which is the real lesson. ChatGPT isn’t a search engine, so stop optimising for one.
It reads your own page for the facts, if it can parse them, and everyone else’s for the opinion, and only when the question is worth a search. Build for that.
And treat all of this, mine included, as a snapshot of a system that changes by the week. The structure holds. The numbers move.
While I was in the traffic I also found a pile of things with nothing to do with sourcing, the bot wall that stops you scripting it, a hidden shopping engine, and 573 live experiments running on the account. Those will be published separately.
I’ve also done similar analysis on Perplexity, Gemini etc. so I’ll be sharing those soon. Subscribe to the newsletter if you want to get them first.
Want to show up in ChatGPT, not just understand how it works?
If you want help applying this on your own site, my agency Snippet Digital takes on this kind of work. Send an enquiry and I will be in touch.
Explore our AI SEO servicesWant my posts to show up more often on Google?
One click and Google will surface this site in your Top Stories.



Norwegian entrepreneur with 20+ years in SEO. Co-founder of Keyword Insights and Snippet Digital. Based in Dubai.