The Three Lives of Schema Markup: A Beginner's Guide to How Google and LLMs Actually Use It
Schema markup is read by 3 completely different systems for 3 completely different purposes. Most articles conflate them. Here is what each one actually does, in plain English, with examples.

Every schema markup article you have read in the last 12 months is partially right and mostly missing the point.
On 11 May 2026, Ahrefs published a causal study of 1,885 pages and found that adding JSON-LD schema produced no significant uplift in AI citations. Half of SEO Twitter is now declaring schema dead. The other half is quoting vendor blogs claiming schema gives you a 2.5x citation boost. Both sides are talking past each other.
The reason they cannot agree is simple. Schema markup is read by 3 different systems for 3 different purposes, at 3 different points in time. Almost nobody writing about it bothers to separate them. So the same word ends up meaning 3 things depending on who is saying it.
This post walks through each one with examples a beginner can follow. By the end you will know what schema actually does, what it does not do, and which of the 3 jobs you are actually paying for when you add it to your site.
What schema markup actually is

Start at the bottom.
Imagine you have written a page about your dog. To you, the page is obviously about a golden retriever called Rex who was born in 2019. To a computer reading the raw HTML, the page is just a block of words and pictures. The computer has to guess what is a name, what is a breed, what is a date. Sometimes it guesses right. Often it does not.
Schema markup removes the guessing. You add a small block of structured data to the page, usually in a format called JSON-LD, that labels the facts in a machine-readable way.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Pet",
"name": "Rex",
"breed": "Golden Retriever",
"birthDate": "2019-04-10"
}
</script>That is it. You are telling the computer that this page is about a pet called Rex, breed Golden Retriever, born April 10, 2019. The computer has nothing left to infer. (I’m using this as an example to explain the concept and worth noting the above example is not valid schema)
Schema.org is the dictionary of available labels (Person, Product, Article, Recipe, Organization, and thousands more). JSON-LD is the format. Google, Bing, and Yandex all recommend JSON-LD because it sits in a separate <script> block and does not interfere with the visible HTML.
So far so simple. Now here is where it gets interesting. Different systems read this block of structured data for different reasons, at different times, in completely different ways. There are 3 of them.
Life 1: Google’s index pipeline
This is the original use case and the one schema was designed for.
When Googlebot fetches your page, it extracts both the visible HTML and the JSON-LD block. These feed two different downstream systems inside Google’s indexing layer. The visible content goes to the ranking pipeline, where systems like BERT, RankBrain, and Neural Matching figure out which queries the page should match. The JSON-LD feeds an entity pipeline that does the following.
- Identifies what entity the page is about. Rex the dog. Or your business. Or this article.
- Checks whether that entity already exists in Google’s Knowledge Graph (the big database of structured facts Google maintains).
- If it does not exist yet, Google may add it as a new entity, but only when enough demand signal supports it. Search interest, corroborating high-authority sources (Wikipedia, Wikidata, established profiles), and link authority do the heavy lifting. Schema alone is almost never the trigger. It strengthens disambiguation when those other signals are already pointing at you.
- If it does, Google updates what it knows about it.
- Uses
sameAslinks inside your schema to connect this entity to other places it lives on the web (your Wikipedia page, your Wikidata entry, your LinkedIn profile).
Deeper version for the curious. Googlebot reads hardcoded JSON-LD on its initial fetch. JavaScript-injected schema queues for Google’s Web Rendering Service (WRS), which renders the page in a second pass and extracts the dynamically generated content. Either path ends in the same place inside Google’s index. The route just differs based on how your page delivers the schema.
JSON-LD is the cleanest, most explicit input to this pipeline, but Google treats it as a signal, not as absolute truth. If your schema conflicts with the visible content, with anchor text from inbound links, or with established authority signals, Google can override or ignore the markup entirely. This is how Google prevents schema spam. Schema’s job is to make the entity unambiguous when the other signals agree with it, not to overrule them.
Worth flagging that schema’s role here has shifted over the years. A decade ago, Google needed structured data to identify entities at all. Since the Knowledge Vault (Google’s 2014 work on extracting facts from unstructured text) and the rise of NLP models like BERT, Google can identify most named entities from your visible prose without help from schema. Where schema still matters is for new entities the Knowledge Graph has not yet learned about, for disambiguating between similar names, and for asserting attribute precision that probabilistic extraction cannot match reliably.
This all happens at index time, which means it runs offline before any user has searched for anything. Google’s servers do this work in batch, in the background.
The output of this pipeline is the stuff most SEOs already know about.
- Rich results in search (recipe cards, FAQ snippets, product carousels, breadcrumb trails)
- Knowledge Panels on the right side of search results for brands and people
- Better entity matching when someone searches for you by an ambiguous name
- Author attribution across Google’s properties
This is why your competitor with proper Organization schema has a Knowledge Panel and you do not. It is also why writers with consistent Person schema get attributed correctly across search results, while writers without it disappear into the void.
This entire layer has nothing to do with AI search or LLMs in the direct sense. It is classic Google infrastructure that has been running since the early 2010s (Schema.org launched in 2011, the Knowledge Graph in 2012). It still works. It still matters. It is where most of schema’s value has historically lived.
At Google Search Central Live Toronto in April 2026, Google structured data engineer Ryan Levering reaffirmed that this pipeline also feeds Google’s own generative AI systems. The session recap lists 4 reasons structured data still matters in the AI era. Structured data is more precise than LLM extraction, especially on complex content like product pricing. It also lets you define information that does not appear on the visible page, including identifiers and metadata. Parsing structured data is much cheaper for Google than repeatedly inferring meaning from raw text. And the right markup focuses attention so machines do not pull in irrelevant context.
Even Google’s AI systems are downstream of the Life 1 pipeline. When Google AI Overviews mentions your brand, it is partly because of the entity work this layer did months earlier.
Life 2: LLM pretraining (indirect)
This is the layer where the public debate gets sloppiest. Schema’s role here is real but indirect, and the direct-survival framing most people use is wrong.
Mark Williams-Cook’s “Schema, LLMs and the Low Bar for Evidence” is the strongest skeptical case on this layer. His core point is that even if schema survived training, individual business mentions are too rare in a 15-trillion-token corpus to meet the repetition threshold a model needs to “learn” anything. He is right on that specific claim. A new dentist in Doncaster with clean schema markup but no Wikidata entry, no Wikipedia article, and no secondary coverage will not be recognised by ChatGPT no matter how clean the JSON-LD is. The mechanism that does survive is narrower than I credited in the original version of this piece. It is still real.
What does not survive. Common Crawl preserves your JSON-LD when it grabs your page. The visible HTML, the meta tags, and the JSON-LD block all sit in the raw snapshot. The next step strips it out. C4 drops any page containing curly brackets, removing most JSON-LD wholesale (the T5 paper documents this). FineWeb extracts “main visible content” only via Trafilatura, which strips <script> tags by default. RedPajama and Dolma document broadly similar cleaning. The proprietary corpora used by OpenAI, Anthropic, and others are not publicly documented but the same conclusion almost certainly holds. The JSON-LD block itself does not survive into training text. Mark is right about this.
What does survive. Schema’s contribution flows through a canonicalisation chain, not through direct ingestion. Your sameAs property links your entity to its Wikidata QID. Wikidata is a primary input to Google’s Knowledge Graph, and the Knowledge Graph reconciles, deduplicates, and canonicalises entity data across Wikidata, Wikipedia, and the wider web. Wikipedia and Wikidata are then heavily represented in LLM training corpora. GPT-3’s training disclosure put Wikipedia at roughly 3 percent by token volume with disproportionate influence because Wikipedia articles are densely interlinked and entity-rich. Academic research on knowledge-graph-augmented language model pretraining (ERNIE, SKILL, KGLM) shows that injecting KG triples into pretraining measurably improves factual recall on entities present in the graph. Recent work also identifies factual recall as the bottleneck for LLM accuracy, which makes entity disambiguation a meaningful upstream lever.
So the chain.
Your schema’s sameAs → Wikidata QID anchoring → Knowledge Graph reconciliation → Wikipedia and Wikidata and secondary canonical sources → LLM training corpora where those sources are heavily weighted → models that recognise your entity.
This is narrower than “schema feeds training” and narrower than what I implied first time round. It only benefits entities that already have Wikidata anchoring. The mechanism is entity disambiguation, not direct fact transfer. Random small businesses without external entity infrastructure do not benefit. For established entities, the chain is supported by both documented training-corpus composition and the academic literature on KG-augmented pretraining.
You cannot point at a specific page in a specific corpus and trace it back to your JSON-LD block. The mechanism is indirect, several steps removed. But for entities with proper Wikidata anchoring, the directional case is sound. Clean, valid schema with consistent sameAs links strengthens the canonicalisation upstream, and that canonicalisation shapes how next year’s GPT or Claude or Gemini talks about your entity.
Life 3: LLM runtime retrieval
Now the third life. This is the one the Ahrefs causal study measured, and the one that drives most of the current debate.
When you ask ChatGPT “What did Suganthan say about WebMCP?”, ChatGPT does not just answer from memory. It fetches the live web. It hits search results, picks pages, fetches them, parses the content, and uses that to construct an answer with citations.
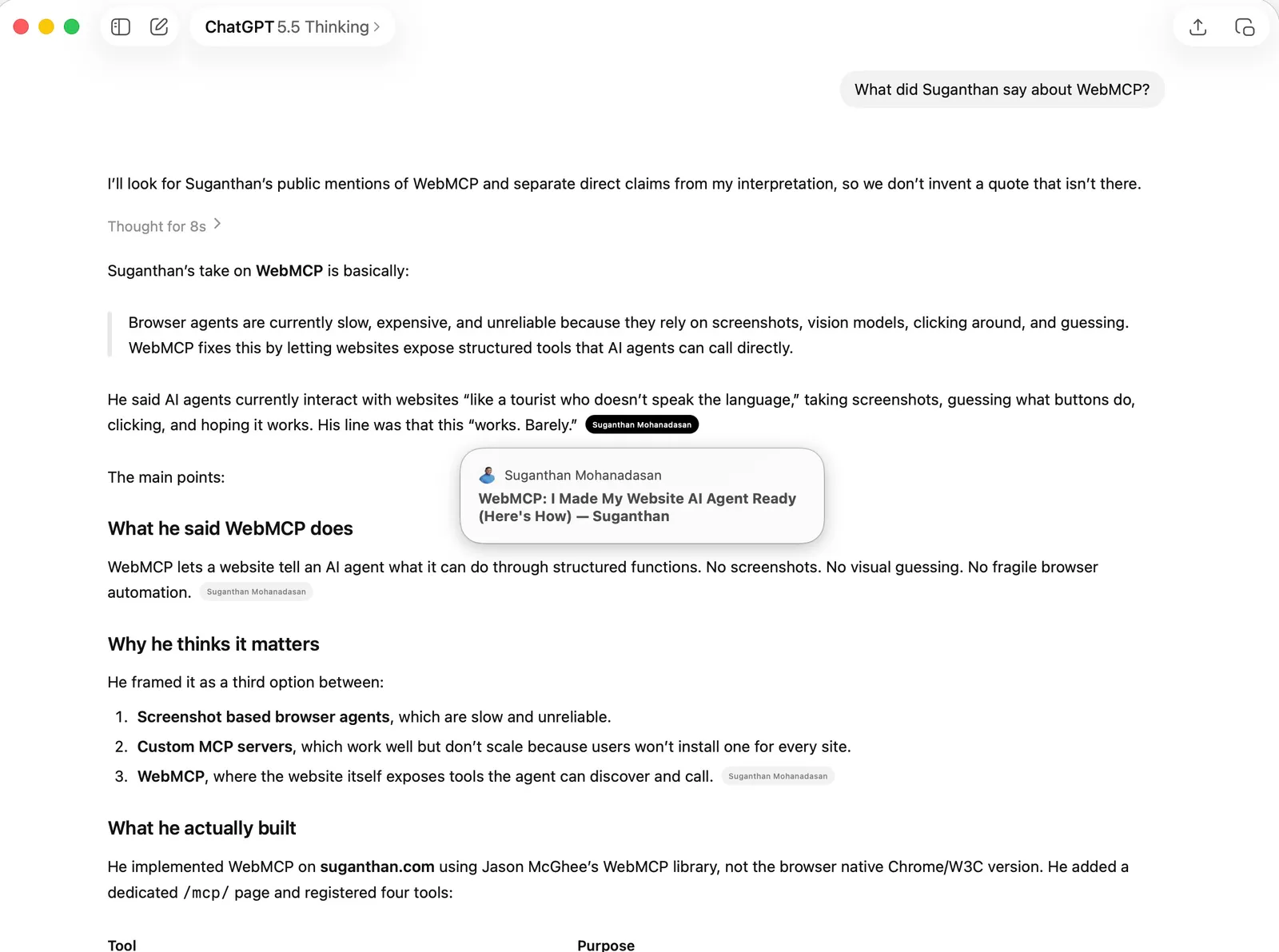
This happens at query time, in real time, while you wait. It is a completely different pipeline from Life 1 and Life 2.
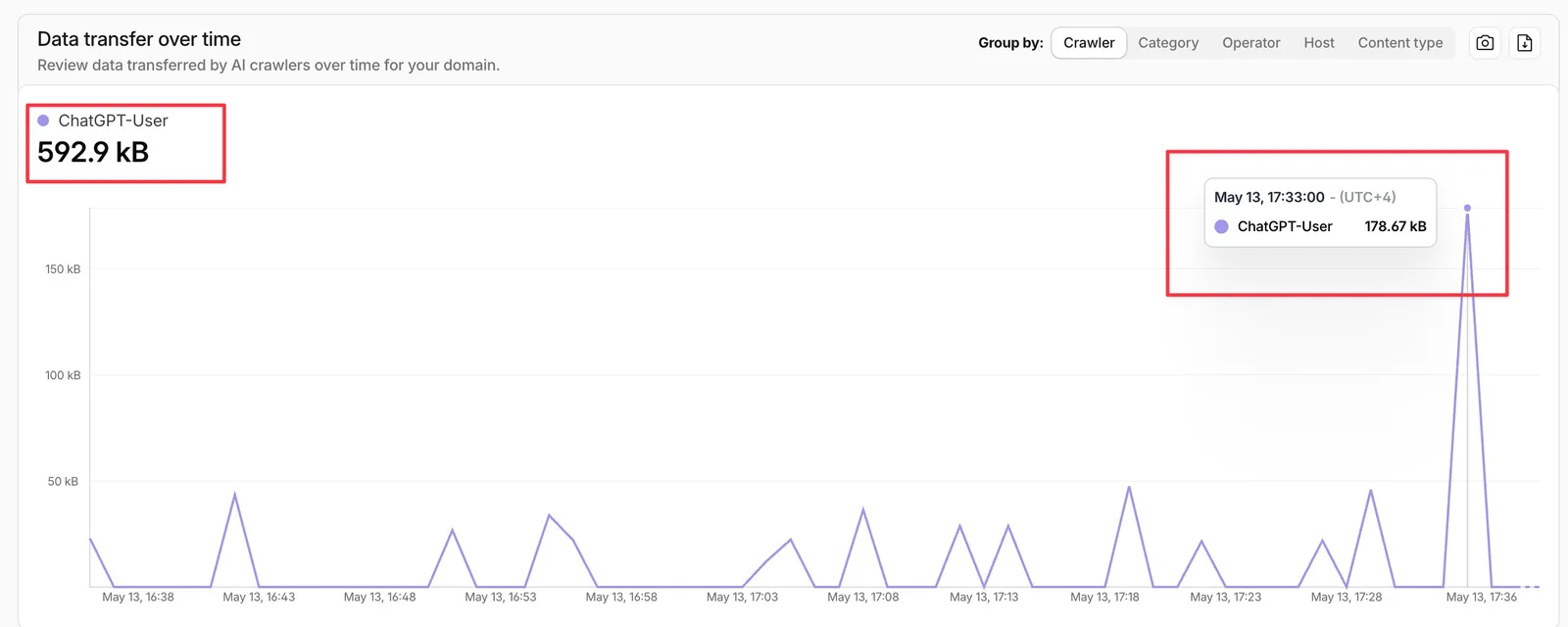
In fact you can see in the logs the exact time it happened. (I did this search around the same time) as i have enabled web search for this to stimulate the actual real time search. You can see from Cloud flare logs the ChatGPT-User used for real time fetching.
The searchVIU experiment tested this in October 2025 across 5 systems (ChatGPT, Claude, Perplexity, Gemini, Google AI Mode). All of them behaved the same way. When the LLM fetched a live page during this retrieval step, it stripped the JSON-LD blocks and relied entirely on visible HTML content. The schema was ignored at this layer.
A caveat. Behaviour depends entirely on the scraping tool the AI is using at that moment. Standard text extractors strip scripts before parsing. Headless browsers that render the full DOM, including client-side JavaScript, can see schema and even pick up structured data that was injected dynamically. Modern AI crawlers vary in capability. The 5 systems searchVIU tested behave one way today. They might switch to full-rendering retrieval tomorrow. Build your site so it works whether the AI reads your schema or not.
That is also what the Ahrefs causal study was measuring. They tracked 1,885 pages that added schema and asked whether AI citations went up over the following 30 days. They did not. ChatGPT +2.2%, Google AI Mode +2.4%, both indistinguishable from zero. Google AI Overviews actually went down 4.6% (small, but statistically significant).
The reason is not that schema is broken. It is that the study measured Life 3, where schema is mostly not used in the way most people think. Life 1 and Life 2 operate on completely different timescales and cannot be detected in a 30-day citation window on pages that were already being cited.
One subtle nuance is worth knowing here. In February 2026, the SEO community lit up over a test popularised by Mark Williams-Cook, with original credit to Richard Barrett. They created a fake company page (DUCKYEA t-shirts) and placed the address ONLY in invalid, made-up JSON-LD. Both ChatGPT and Perplexity extracted and returned the address when asked. The reason is mechanical. LLMs tokenise the entire HTML response, including the <script> blocks that contain JSON-LD. They can see the text inside schema. But they do not parse it as structured data. They read it as plain text alongside the rest of the page.
So at Life 3, schema is functionally text. It is not being interpreted as structured information. The model is just reading the characters.
The picture changes for Google’s own AI surfaces. At Search Central Live Toronto in April 2026, Google structured data engineer Ryan Levering said, verbatim: “Schema is used as context served to models when doing fanouts” (per the Schema App recap and the Search Central recap). That is a Google search engineer, on record, saying schema is served to their generative models during query-time fanout retrieval. AI Mode and AI Overviews are downstream of that pipeline. The picture splits. Third-party LLMs fetching your page in real time strip JSON-LD and read visible HTML only (DUCKYEA and searchVIU both confirm this). Google’s own first-party AI surfaces use schema as runtime context. Same protocol, different consumers.
Google’s implementation is imperfect even for itself. The Ahrefs negative result above sits in this same family. Mark also documents in his piece an AI Overview that contradicted Google’s own Business Profile data on the same SERP. Schema is fed in as context but the wiring between KG signals and AI generation is not yet reliable. The direction is real. The execution is uneven.
Where the confusion comes from
Most of the schema-for-AI debate happens because writers, and the tool vendors paying them, conflate these 3 lives.
You see headlines like “Schema gives you a 2.5x boost in AI citations”. That number comes from correlation studies and is then served up as if schema causes citations. It does not. Pages with schema are usually also pages with strong content, decent backlinks, established entity presence, and Knowledge Graph membership. The schema travels with all the other signals. Take it away and you would still get cited, because the other signals are doing the heavy lifting.
The other way round, when Ahrefs ran a clean causal study and found no significant uplift, the reaction was equally wrong. “Schema is dead” only makes sense if you assume schema’s job was Life 3 (forcing AI citations through runtime fetches). It was not. It still is not. The Ahrefs study explicitly flagged in its limitations that it did not test Life 1 or Life 2 effects.
Gianluca Fiorelli wrote the cleanest explanation of this so far. His argument is that the Ahrefs study is methodologically right but tests the wrong thing. Schema, in his words, is “entity infrastructure”, not a citation lever.
That phrase is the one that should reset the whole conversation.
A simpler mental model
Forget the AI hype for a second. Think of schema markup as business registration, not advertising.
You do not register your company with the government because you expect a direct sales boost. You register because being a formally recognisable legal entity is the foundation that other things sit on top of. You can sign contracts. You can open a bank account. You can be referenced in legal documents and tax filings. None of that produces revenue by itself. All of it is required for the systems that DO produce revenue to function.
Schema works the same way. Being a formally recognisable structured entity is the foundation for everything that follows. Google’s Knowledge Graph can index you properly. The canonical entity stores that feed AI training treat your data as high confidence. Entity disambiguation works in your favour when someone searches for an ambiguous name.
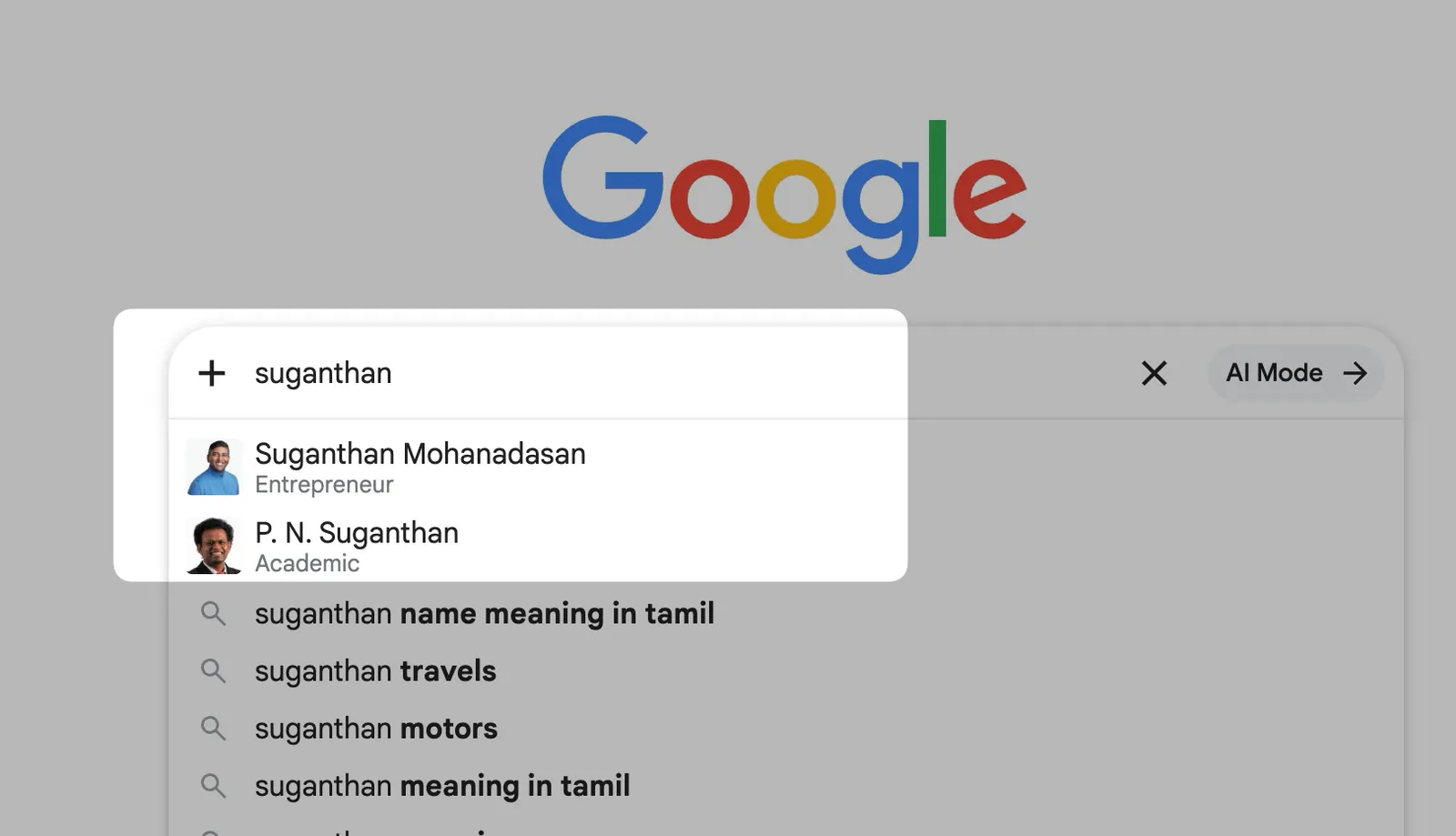
As you can see there are two people with the same name and only one tall, dark and handsome SEO guy ;)
This is partly because of how I have implemented my person schema. Over time Google can tell the SEO Suganthan from the Academic Suganthan.
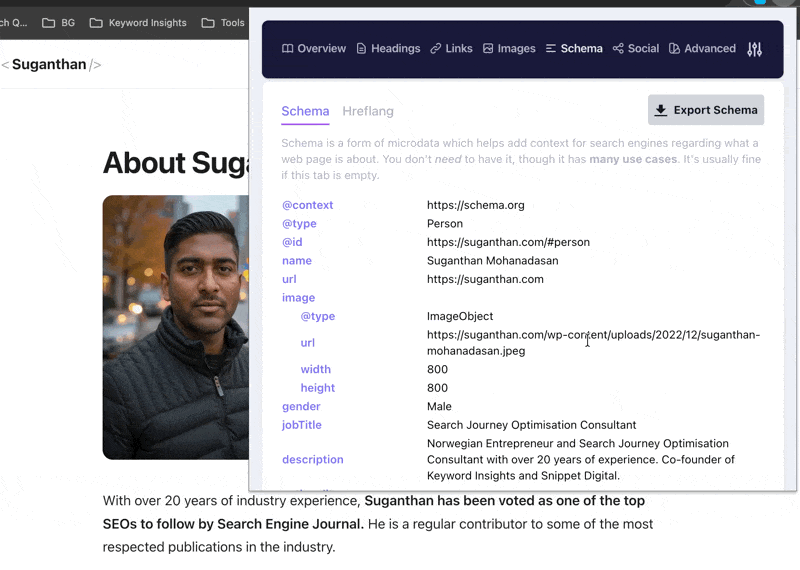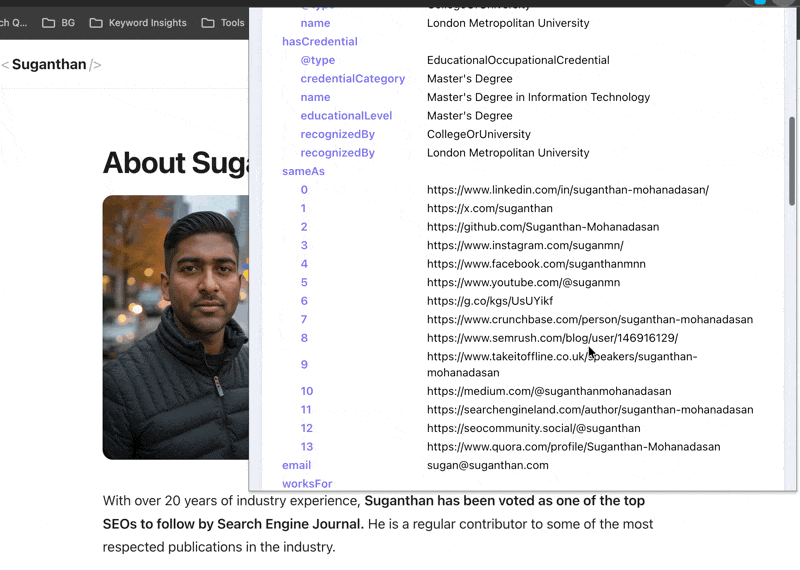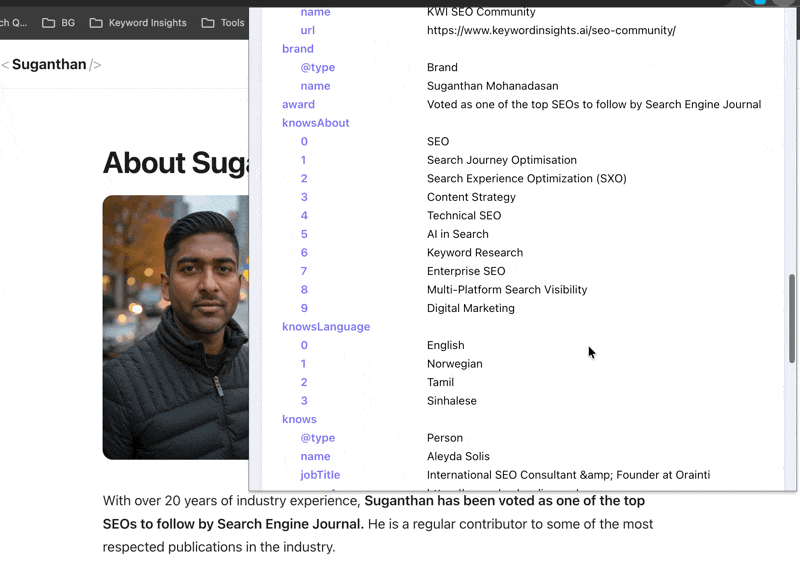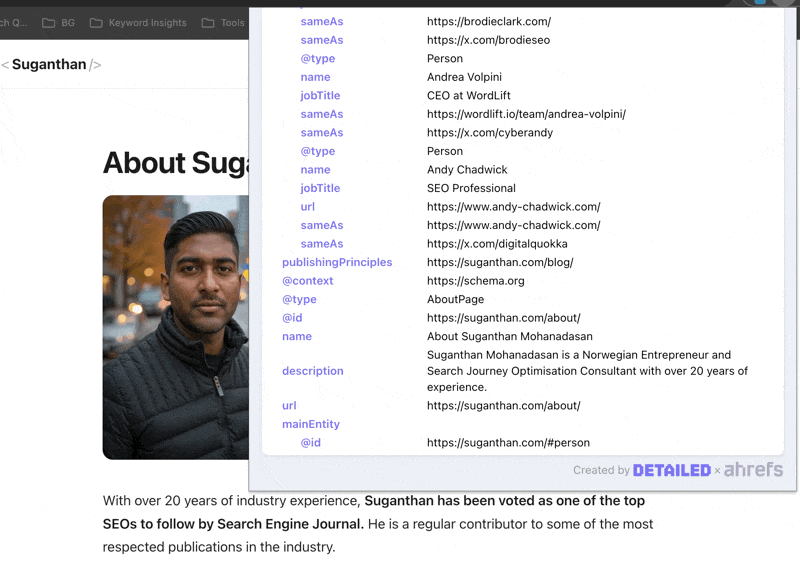
Adding schema does not directly cause citations or rankings. It makes you legible to the systems that decide whether to feature you. Those are very different things.
What schema actually does for you
Broken down by life.
Life 1 (Google’s index pipeline). This is where schema pays off fastest. Rich results in Google search (recipe cards, product carousels, review snippets, breadcrumbs) all require the relevant schema types. A Knowledge Panel for your brand needs Organization schema with sameAs links to Wikipedia, Wikidata, and your social profiles. Author attribution across Google’s properties only works when you have Person schema connected to your articles.
Action - Implement Organization, Person, Article, and Breadcrumb schemas at minimum. Add sameAs links to every authoritative profile you have. More importantly, connect these schemas to each other using @id node identifiers so search engines understand the relationships. An isolated Person block, an isolated Article block, and an isolated Organization block tell Google three separate stories. A nested graph with @id references says they are all part of the same entity. This is the difference between schema as decoration and schema as entity infrastructure. Verify in Google’s Rich Results Test.
Life 2 (LLM pretraining, indirect). You cannot directly measure your impact on training corpora, and your JSON-LD will not survive cleaning into the training text anyway. The real lever is Wikidata anchoring. If your entity meets the notability bar, get a Wikidata entry. Use sameAs in your schema to link to it. Build Wikipedia presence where the notability threshold allows. These are the canonical sources the chain actually flows through, and they are the ones LLM training corpora weight heavily. As a softer relative indicator, Metehan Yeşilyurt’s free CC Rank Checker shows your Harmonic Centrality rank and PageRank inside Common Crawl’s WebGraph (lower is better). It is link-graph based rather than schema-specific, so it tells you how visible your domain is to the upstream of training data, not how clean your structured data is. Useful as a relative reading, not as a target.
Action - Keep your schema clean, consistent, and present across the entire site, not just on a few key pages. Do not change @id URLs once they are set, as those are how the model is learning to identify your entity across pages. Treat your entity identity as a long-term asset.
Life 3 (LLM runtime retrieval). Schema does not directly help here. Your visible content does. Clean HTML, good headings, natural language, decent formatting. That is what AI assistants actually read at retrieval time.
Action - Write content that is structured semantically with proper headings, lists, and paragraphs. Answer questions directly in visible text. Do not try to hide facts in schema and expect AI to find them. It can, technically, but it is unreliable.
One more risk worth knowing about. Google has long maintained that structured data must match the content visible on the page. Adding facts in schema that do not appear in visible HTML is a content parity violation and can trigger a manual action against your site. The Williams-Cook test was a research demonstration, not a deployment strategy. If a fact matters, put it in visible HTML and mirror it in schema.
What to do by site type
Publisher or blog. Article schema with proper Author markup. Get your Person schema right with sameAs links to your professional profiles. This earns you Knowledge Graph membership and author attribution. Do not expect schema to drive AI citations directly. The content does that. The schema makes sure the citations get attributed to you when they happen.
Ecommerce. Product schema is non-negotiable. Add ItemList, OfferCatalog, and AggregateRating where applicable. This unlocks Life 1 rich results which still send enormous amounts of traffic. AI shopping experiences (ChatGPT, Perplexity) are still early, but Bing and Google are already using your structured data when responding to shopping queries.
B2B or SaaS. Organization schema with sameAs to every credible profile you have (LinkedIn, Crunchbase, Wikipedia, Wikidata). SoftwareApplication schema on your product pages. FAQPage schema on those pages too, even though Google killed the visual rich result on 7 May 2026. The SERP feature is gone for everyone, but the schema itself remains valid code, still parsed by Google and AI systems. It has shifted from a visual SEO tactic to entity infrastructure for Life 1 and Life 2. Leave your existing FAQ schema in place and keep adding it to new pages.
Heads up on the phased removal though. FAQ reporting in Search Console and the Rich Results Test both go away in June 2026, and Search Console API support for FAQ drops in August 2026. Do not panic when those disappear from your dashboards. The schema itself is still being read.
Personal brand. Person schema linked from your homepage to your articles. sameAs to LinkedIn, X, GitHub, anywhere you publish. This is the cheapest and highest-leverage schema work you can do. Almost nobody bothers with it, which is exactly why it works.
Closing
Schema markup is not dead. It is also not a magic AI citation lever.
It is entity infrastructure. It makes you formally recognisable to the systems that decide whether and how to feature you. 3 of those systems depend on your schema right now. Google’s index pipeline reads it directly for rich results, Knowledge Graph membership, and entity disambiguation. LLM pretraining inherits it indirectly through the Knowledge Graph chain. LLM runtime retrieval mostly strips it, though the picture there depends on which scraper the AI is using on the day.
If you treat schema as advertising you will be disappointed. If you treat it as registration, the value compounds quietly in the background for years.
Add it cleanly. Keep it consistent. Do not expect overnight wins. Then go write good visible content and let both work together.
That, properly, is how schema works.
Want schema done properly on your site?
If you want help applying this on your own site, my agency Snippet Digital takes on this kind of work. Send an enquiry and I will be in touch.
Work with meWant my posts to show up more often on Google?
One click and Google will surface this site in your Top Stories.



Norwegian entrepreneur with 20+ years in SEO. Co-founder of Keyword Insights and Snippet Digital. Based in Dubai.