I Shipped Agentic Resource Discovery on This Site (And a Client Found Me)
Google and 10 others shipped Agentic Resource Discovery. I added an ai-catalog.json to this site, validated it against the official tool, and a reference client discovered my capabilities. Here is the build and the Cloudflare catch.
Update (20th June 2026): Now with two free tools, an Agentic Resource Discovery Checker to see whether AI agents can find your own site, and an Agentic Web Search to find agents and tools across the web. Plus a field test of all 11 launch companies to see who actually shipped a catalog, and the federated registry behind it all. The federated half is no longer just a promise. Full changelog at the bottom.
On 17 June 2026, Google and 10 other companies published Agentic Resource Discovery, a spec for how AI agents find tools, agents, and APIs across the web.
Within 2 days I had it running on this site.
Then I pointed the official Hugging Face client at my domain, and it read my own capabilities straight back to me.
It works.
The catch is what happens when a slightly different client tries the same fetch, and Cloudflare decides it does not like the look of it.
Here is the whole build, the proof it runs, and the part nobody is talking about yet.
Agentic Resource Discovery Explained in a minute
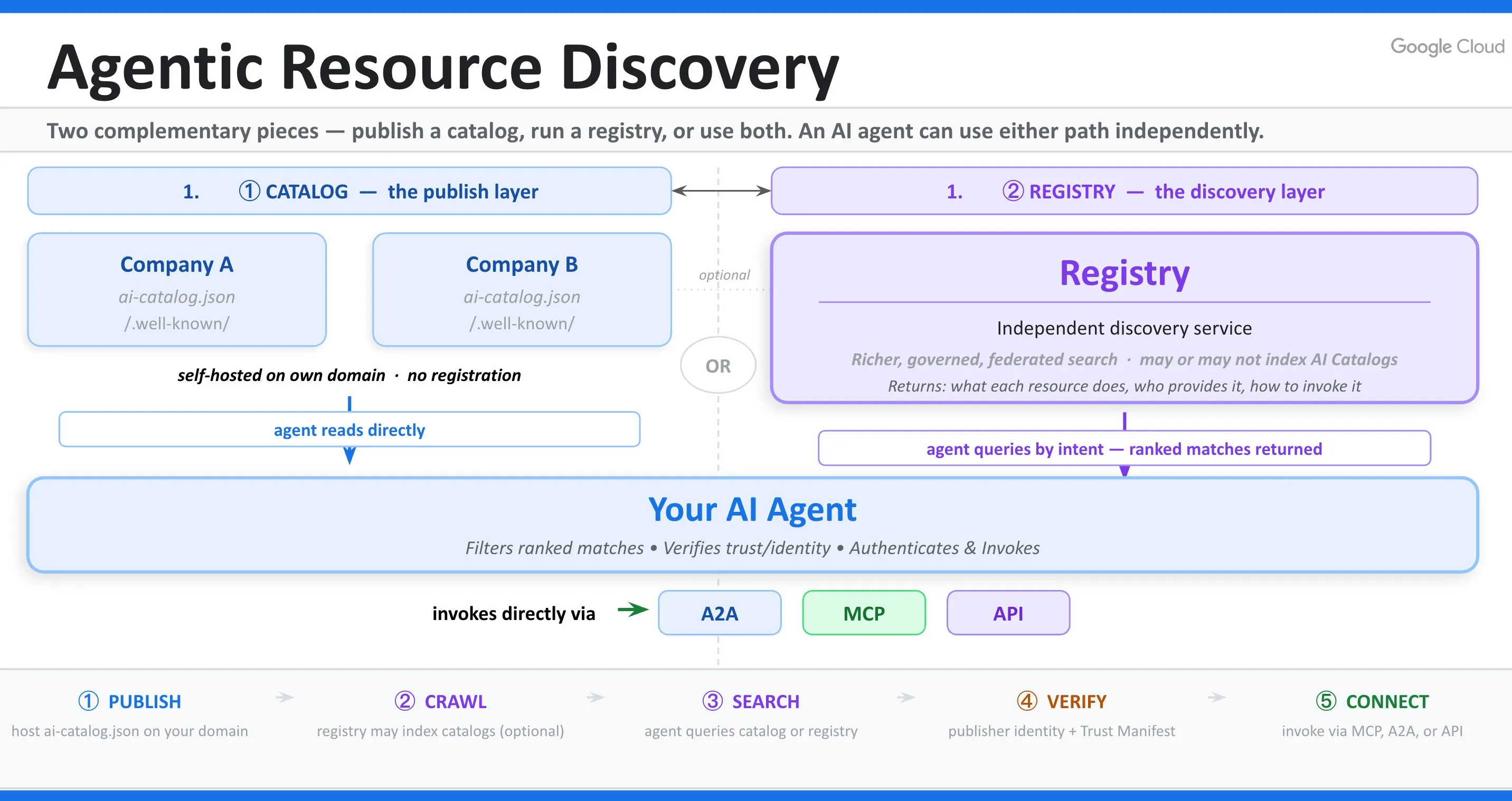
Think of the web as a hotel. Every website is a guest, and each one can do something useful. An AI agent is the concierge, sent up to run an errand for whoever it is helping. The old problem is simple. The concierge cannot know which guest does what without knocking on all 400 doors.
ARD fixes that with 2 things.
First, every guest pins a small card by their door that lists what they can do, something like “I can search an SEO blog, here is how to ask me”. That card is the file you publish.
Second, the hotel keeps a directory at the front desk, so the concierge can walk up and ask one question, “who here can transcribe audio”, and get a ranked list back. That directory is what the spec calls a registry.
In the site’s own terms, the card by the door is a static ai-catalog.json at a well-known path. It lists what your site offers an agent, an MCP server, an A2A agent, an API, even a nested catalog, and points at each one. The front desk is a registry that crawls those cards and answers natural-language queries, so an agent asks “who can do X” and gets a ranked answer.
The first half is a file you write. The second half is the agentic web’s version of a search engine, and it’s the new part. The draft has 11 companies behind it, including Microsoft, GitHub, Hugging Face, Nvidia and Salesforce, on a Linux Foundation data model. That spread is why this one is worth taking seriously.
Why Agentic Resource Discovery is not your api-catalog
The names are one letter apart, and everyone is about to mix them up.
api-catalog (RFC 9727) | ai-catalog.json (ARD) | |
|---|---|---|
| Lists | Your public APIs | Tools, skills, MCP servers, A2A agents, sub-catalogs |
| Standard | IETF | Google and 10 others, Linux Foundation model |
| Discovery | A static list you publish | A static list plus registries that crawl and rank everyone |
| Identity | None | Domain ownership as the trust root |
I already serve an api-catalog on this site, and it stays exactly where it is. ARD is not a rename of it. It is the layer above, and the two sit side by side.
Why this site was a soft target
ARD only matters if your catalog points at something real. Most content sites have nothing to list, so their ai-catalog.json would be an empty shelf.
This site is not one of them. From the agent-ready build it already serves an A2A agent card at /.well-known/agent.json and an MCP server card at /.well-known/mcp/server-card.json, both live, both pointing at the WebMCP endpoint at /mcp/. ARD’s entire job is to advertise exactly those. So my catalog points at working capabilities, which is the difference between a demo and a real one.
The file
Here is the catalog, trimmed to 2 of its 3 entries. The full version is live at /.well-known/ai-catalog.json.
{
"specVersion": "1.0",
"host": {
"displayName": "Suganthan Mohanadasan",
"identifier": "did:web:suganthan.com",
"documentationUrl": "https://suganthan.com/mcp/"
},
"entries": [
{
"identifier": "urn:ai:suganthan.com:agent:blog-agent",
"displayName": "Suganthan Blog Agent",
"type": "application/a2a-agent-card+json",
"url": "https://suganthan.com/.well-known/agent.json",
"description": "A2A agent card for searching, retrieving, and reading my blog posts and notes on SEO, AI SEO, and the agentic web.",
"capabilities": ["search_posts", "list_posts", "get_post", "get_site_info"],
"representativeQueries": [
"find an agent that can search an SEO blog",
"what has this site published about the agentic web"
],
"version": "0.1.0"
},
{
"identifier": "urn:ai:suganthan.com:server:blog-mcp",
"displayName": "Suganthan's MCP Server",
"type": "application/mcp-server-card+json",
"url": "https://suganthan.com/.well-known/mcp/server-card.json",
"description": "MCP server with tools to search posts, list posts, fetch a post by slug, and read site and author info.",
"representativeQueries": [
"find an MCP server that can search a blog about SEO",
"get the full text of an SEO blog post by slug"
],
"version": "1.0.0"
}
]
}Here are 2 details that I missed and wasted a lot of my time.
specVersion is "1.0", not 0.9. The spec document is at v0.9 draft, but the schema pins the wire-format version to 1.0, and validation fails on anything else. Read the schema, do not infer the version from the spec’s own heading.
Every identifier is a URN matching a strict pattern, urn:ai:<publisher>:<namespace>:<name>, where the publisher segment has to be your domain. The representativeQueries are not decoration. They are the text a registry embeds to match natural-language searches, so they are worth writing as the questions a real person would type.
The 4 ways to advertise it
The spec defines 4 discovery methods. I deployed 3 of them plus an HTTP Link header, and skipped the fourth.
The well-known file is the main one. On top of that, a directive in robots.txt:
Agentmap: https://suganthan.com/.well-known/ai-catalog.jsonA link in every page head:
<link rel="ai-catalog" href="/.well-known/ai-catalog.json">And the same pointer as an HTTP Link header, served from Cloudflare’s _headers next to the api-catalog one that was already there:
Link: </.well-known/ai-catalog.json>; rel="ai-catalog"The one I skipped is DNS. ARD lets you publish Service Binding records so an agent can find your catalog from a DNS lookup alone, no HTTP needed. It’s clever, but it meant touching DNS for a draft spec, and I was not ready to do that for a file that already has 3 other front doors.
did:web, because identity is the whole point
ARD’s trust model is domain ownership. If a catalog lives at suganthan.com, the claim is that whoever controls that domain controls the catalog. To make that concrete I set the host identifier to did:web:suganthan.com and shipped a did.json so the identifier actually resolves rather than dangling.
The heavy version of this, the signed trustManifest with SPIFFE identities and compliance attestations, is the optional enterprise layer. I did not ship it, because for a personal site, serving the document from the domain itself is the proof. That is the entire appeal of did:web. The domain is the root of trust, and you already own it.
Does it validate? Yes
I ran 2 checks. First, the file against the official JSON Schema, Draft 2020-12, which passed with no errors. Then the official conformance tool from the spec repo, run against the live file:
=== Validating Manifest: /.well-known/ai-catalog.json ===
✓ Manifest parsed successfully as valid JSON.
✓ Strict JSON Schema validation passed.
• Found 3 entries to validate.
Entry: Suganthan Blog Agent
✓ Valid URN format. Publisher: 'suganthan.com', Name: 'blog-agent'.
✓ Correct Value-or-Reference delivery format (using url).
...
=== Conformance Validation Summary ===
CONFORMANCE STATUS: PASS
Validated with 0 critical specification errors and 1 warnings.The one warning is worth keeping rather than hiding. My third entry is the site’s OpenAPI spec, and its media type, application/vnd.oai.openapi+json, is not one of ARD’s standard discovery types. ARD recognises MCP servers, A2A agents, nested catalogs and registries as first-class. A raw REST API rides along and gets flagged as non-standard. That tells you something true about the spec. It’s built agent-protocol first, not API first. I left the entry in because the API is real, and a warning is honest where a deletion would be tidy.
Does a client actually find me? Also yes
This is the moment ARD stops being a PDF. I installed the Hugging Face reference client and pointed its navigate command, which does automatic catalog discovery, at my live domain:
hf-discover navigate https://suganthan.com "find an MCP server that can search an SEO blog"It fetched my catalog and handed back my own capabilities:
{
"discovered": [
{ "kind": "catalog",
"url": "https://suganthan.com/.well-known/ai-catalog.json",
"status": "ok" }
],
"results": [
{ "identifier": "urn:ai:suganthan.com:agent:blog-agent",
"displayName": "Suganthan Blog Agent",
"type": "application/a2a-agent-card+json", "score": 50 },
{ "identifier": "urn:ai:suganthan.com:server:blog-mcp",
"displayName": "Suganthan's MCP Server",
"type": "application/mcp-server-card+json", "score": 50 }
]
}To check it was matching rather than just dumping the file, I asked it something my site cannot do, “transcribe audio to text”. It dropped the agent and the API and returned only the MCP server, the closest of a bad set. So there is real selection happening, not a blind echo.
A third-party client, run cold against my domain, discovered and understood what this site can do for an agent. That is the spec working end to end.
Oops! Cloudflare blocked the validator
The first time I ran that conformance tool against the live URL, it did not validate anything. It got a flat 403.
The file was fine. curl pulls it down with a 200 all day. The tool was getting blocked because of who it said it was. It fetches with Python’s standard library, whose user-agent is Python-urllib, and Cloudflare’s managed bot rules treat that as a bad actor and turn it away at the edge before it ever reaches the file.
I tested the same URL as a series of different clients:
| Client user-agent | Response |
|---|---|
Python-urllib/3.11 (the conformance tool) | 403 |
Browser (Mozilla/5.0) | 200 |
ClaudeBot, GPTBot | 200 |
curl, empty user-agent, the Hugging Face client | 200 |
Read that table again.
The named AI crawlers walk straight in. A blank user-agent walks in. The official conformance tool for the spec you are implementing does not. Same file, different doorman.
That is the gap between publishing a catalog and having it be discoverable. Shipping the file is necessary and nowhere near sufficient. If you sit behind Cloudflare, or any WAF with managed bot rules, a registry crawling you with a stock HTTP library can be turned away while you sit there thinking you are live.
The fix is to allowlist your /.well-known/ paths for these clients, or to lean on the fact that the real registries identify themselves properly. The Hugging Face client got through because it sends its own user-agent. The reference validator did not, because nobody changed the default. Check this yourself, because it is the step everyone will skip.
The limitation
What I have proved is the publisher half and the client half. My catalog is valid, it is discoverable, and a real client pointed at my domain reads it correctly.
What I have not proved is the headline the spec is selling, that a registry indexes the open web and an agent finds me cold, never having heard of this site. To be fair, that machinery is only 2 days old. Hugging Face’s hosted registry only indexes its own Spaces, and no public registry is crawling the open web yet.
So the federated-search half is a promise, not yet a demo.
The upside is that the catalog is already sitting there for the day a public registry starts crawling. Watch this space.
Who actually deployed it (new)
Three days after the spec dropped, I checked all 11 launch companies for a catalog at the address an agent would actually try, /.well-known/ai-catalog.json on the main domain. None of them serve one.
| Company | Catalog on the main domain |
|---|---|
| Hugging Face | 401, no public catalog, their registry lives on a separate subdomain |
| Google, Microsoft, GitHub, Salesforce, Databricks, Snowflake, Cisco | 404 |
| Nvidia, ServiceNow, GoDaddy | 403 |
Signing a launch announcement and deploying files to a Fortune 500 domain are different sports. Just 3 days in, that gap is the story. Hugging Face is the exception, and a useful one. They skipped the file on their main domain and built the front desk instead, a live registry that indexes thousands of running Spaces and answers ARD queries today. So the federated half I called a promise just above is now a demo. One company deep, but it works.
I built the registry, and a checker for you (new)
The spec is blunt that there is no central directory. Every site can run its own. So I wrote one, a few hundred lines of Python that crawl a list of sites, read their catalogs, and answer a plain-English query across all of them.
The interesting part is federation. When a catalog points at another registry, like Hugging Face’s, it queries that one too and blends the results. Ask it for an MCP server that searches an SEO blog and my own server tops the list, with Hugging Face’s live Spaces folded in underneath. It is on GitHub if you want to run it.
While wiring my registry into Hugging Face’s, every call failed. Their published catalog advertises its registry at a host that returns 404, a stale address someone left in a config, while the working service sits right next door. I reported it. A fair reminder that this whole layer is 3 days old and held together with the usual string.
The CLI is for people who like a terminal. For everyone else I built the Agentic Resource Discovery Checker.
Type your domain and it runs this whole post against your own site, all 4 discovery signals, the catalog validation, and the firewall test that caught my own Cloudflare block. It turns what is missing into a list you can act on.
If you would rather find agents and tools than check your own site, the same engine powers a hosted Agentic Web Search
Should you ship this yet?
If your site does not expose an MCP server, an A2A agent, or an API, your ai-catalog.json is an empty shelf. Skip it, and revisit when you have something to list.
If you do expose any of those, and more sites will, it’s a 20-minute job that costs nothing and gets you in front of the registries before they arrive. The order that worked for me → Serve a valid ai-catalog.json -> point every entry at a real capability → run the conformance tool until it passes -> advertise the file more than one way, and then, if you are behind a WAF, confirm a plain HTTP client can actually fetch it.
That last check is the one that separates a catalog that exists from one that works.
This is the next layer on top of making your site agent-ready and shipping WebMCP.
The protocols keep stacking. The good news is that each one is a small file, and most of the work is deciding whether you needed it at all.
Just only small problem.

Changelog
Update, June 2026 Built the Agentic Resource Discovery Checker and a hosted Agentic Web Search, free tools that check a site and search the agentic web. Tested all 11 launch companies and found none serving a catalog on their main domain yet, with Hugging Face the only exception, running a live registry on a subdomain. Open-sourced a federated ARD registry that searches this site’s catalog and Hugging Face’s live index in one query, and reported a bug in Hugging Face’s deployment where the published catalog points at a dead host.
Want your site built to be found by AI agents, not just crawled by them?
If you want help applying this on your own site, my agency Snippet Digital takes on this kind of work. Send an enquiry and I will be in touch.
Work with meWant my posts to show up more often on Google?
One click and Google will surface this site in your Top Stories.



Norwegian entrepreneur with 20+ years in SEO. Co-founder of Keyword Insights and Snippet Digital. Based in Dubai.